Online Hunmarc import / távoli keresés
1. Importálandó rekordok
Az online Hunmarc import Hunmarc vagy MARC21 szabványú bibliográfiai rekordok feldolgozására, és TextLib adatbázisba betöltésére képes. A Hunmarc rekordok forrása háromféle lehet.
- Tetszőleges forrásból beszerzett Hunmarc állomány
- A TextLib Keresés - Távoli (z39.50+tlwww) pontjában végzett keresés
- A TextLib Keresés - Távoli (webes) pontjában végzett keresés
1.1. Meglévő Hunmarc állomány
Egy Hunmarc állomány forrása sokféle lehet. Talán a leggyakoribb a Kelló adatbázis szolgáltatása, amelynek keretében a tőlük vásárolt könyvekhez tartozó bibliográfiai rekodok Hunmarc formában letölthetők a weblapjukról.
Ezen kívül a MOKKA, az ODR és szinte bármelyik könyvtár web OPAC-jában indított keresés végén a találatokhoz tartozó bibliográfiai rekordokat letölthetjük Hunmarc formátumban és elmenthetjük egy állományba.
1.2. Távoli keresés z39.50 klienssel
A Keresés - Távoli (z39.50+tlwww) menüpontban indított keresés a kiválasztott könyvtárakban zajlott keresés eredményével automatikusan elindítja az online Hunmarc importot.A munka az alábbi ablakban indul:
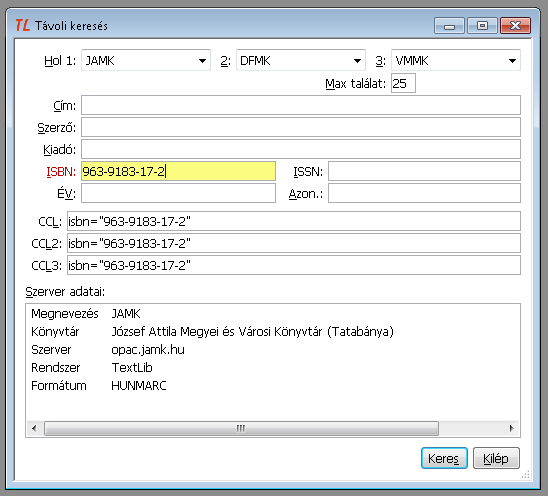
A Hol 1, 2, 3 mező beállításával választhatjuk ki, hogy mely távoli adatbázisokban kívánunk keresni. A sorrend erősorrend is, mert a keresés abbamarad, amint a soron következő könyvtárból találat érkezik. A könyvtárak listáját a TextLib szerver programot futtató számítógépen találjuk:
- Windows: \Program Files\TextLib Windows Szerver\exe\tav-ker.cfg
- Linux: /usr/share/textlib/exe/tav-ker.cfg
A lista szabadon bővíthető, amennyiben ismerjük a keresésbe bevonni kívánt könyvtár szükséges adatait. A listában jelenleg a következő könyvtárakat találjuk:
- MOKKA - Magyar Országos Közös Katalógus - Corvina
- OSZK - Országos Széchényi Könyvtár (Budapest) - Amicus
- FSZEK - Fővárosi Szabó Ervin Könyvtár (Budapest) - Corvina
- MTA - Magyar Tudományos Akadémia Könyvtár és Információs Központ (Budapest) - Aleph
- DFMK - Deák Ferenc Megyei és Városi Könyvtár (Zalaegerszeg) - TextLib
- JAMK - József Attila Megyei és Városi Könyvtár (Tatabánya) - TextLib
- VMMK - Vörösmarty Mihály Könyvtár (Székesfehérvár) - TextLib
- PAKS - Paksi Pákolitz István Városi Könyvtár (Paks) - TextLib
- VARPALOTA - Krúdy Gyula Városi Könyvtár (Várpalota) - TextLib
- KULKER - Budapesti Gazdasági Egyetem Külkereskedelmi Kar Könyvtára (Budapest) - TextLib
- DFMK-z3950 - Deák Ferenc Megyei és Városi Könyvtár (Zalaegerszeg) - TextLib+z39.50
- VFMK - Verseghy Ferenc Könyvtár (Szolnok) - Corvina
Megjegyzés:
- A MOKKA-ban ugyanannak a dokumentumnak különböző könyvtárakból származó leírása gyakran nincs összevonva, így még az ISBN alapján indított keresés is könnyen eredményezhet több találatot.
- A Corvina Z39.50-ben keresés mindig szavasan történik. Ha pl. a Cím mezőben keresünk az 'Enni' szóra, akkor nem csak az így kezdődő címeket kapjuk meg (pl.: 'Enni jó'), hanem azokat is, amikben szerepel az 'enni' szó (pl.: 'Adjatok nekik enni')
- A Corvina z39.50-ben nem érdemes a névelőket tartalmazó címet névelővel együtt megadni, mivel ilyenkor a keresés annyira lassú, hogy legtöbbször timeout hibát eredményez. Névelő nélkül keresve megtalálhatjuk a könyvet. Pl. 'A család' helyett csak 'család'-ra keressünk!
- Az ékezetes betűket a Corvina z39.50 jól kezeli. ISO-8859-2 karakterkészletben várja a keresőkérdést. A megfelelő karakter konverziót a TextLib elintézi.
- Az Amicus z39.50 (OSZK) nem szavasan keres, hanem csonkoltan, vagyis csak a megadott szöveggel kezdődő címeket találja meg (az 'Enni jó'-t igen, de az 'Adjatok neki enni'-t nem)
- Az Amicus z39.50 (OSZK) keresés figyelmen kívül hagyja az ékezeteket. Ha 'bor'-t keresünk, a 'bór' és a 'bőr' is meg lesz találva.
- Az eredmény rekordokat minden rendszer ANSEL kódkészletben küldi. Ennek megfelelő konverziót a TextLib elintézi.
A könyvtárat kiválasztva az ablak Szerver adatai mezőjében olvashatjuk a könyvtár adatait, valamint a keresésre vonatkozó speciális jellemzőket. A textlibes könyvtárakban többkötetes könyvek keresésekor, illetve analitikusan feltárt kötetek keresésekor többféleképpen járhatunk el, attól függően, hogy a többkötetes összes kötetére vagy csak valamelyikére, illetve az analitikák mindegyikére vagy csak valamelyikére van szükségünk:
- A közös adatot keresve eredményül kapjuk a közös adatot és külön kérés nélkül az összes kötetet, továbbá valamennyi kötet összes analitikáját, ha van.
- Valamelyik kötetet keresve csak azt a kötetet kapjuk, továbbá külön kérés nélkül az összes analitikáját, ha van.
- Valamelyik analitikát keresve csak azt az analitikát kapjuk.
A különbségtételnek ez a lehetősége a nem textlibes könyvtárakban nincs meg, azokban mindenképpen külön kell megkeresnünk a közös adatot és egyesével a köteteket.
A DFMK-ban kétféleképpen kereshetünk, a z39.50 szerver használatával zajló keresés a nem textlibes könyvtárakéval rokon.
Amennyiben nem akarjuk, nem szükséges a Hol mező mindhárom előfordulását kitölteni.
A kereséshez töltsünk ki egyet vagy többet a rendelkezésre álló mezők közül. Ha többet is kitöltünk, akkor azok között a program automatikusan és megváltoztathatatlanul ÉS kapcsolatot létesít. A CCL... mezők a keresés CCL nyelvi megfelelőjét mutatják a keresőmezők kitöltése közben, ugyanakkor lehetőséget adnak CCL nyelvű kérdés megfogalmazására a keresőmezők kitöltése nélkül is.
A keresés elindításához nyomjuk meg a Keres gombot. A sikertelen keresést az ablak alsó szegélyén megjelenő nincs találat üzenet jelzi, siker esetén a találatokat egy új Távoli keresés című ablakban kapjuk meg.
A keresés eredményességnek feltétele, hogy a címzéshez szükséges, a tav-ker.cfg-ben leírt porton keresztül az adatforgalom a saját intézményünkben engedélyezett legyen.
1.3. Távoli webes keresés
A Keresés - Távoli (WEB-es) menüpontban indított keresés a kiválasztott könyvtárakban zajlott keresés eredményével automatikusan elindítja az online Hunmarc importot.
A munka az alábbi ablakban indul:
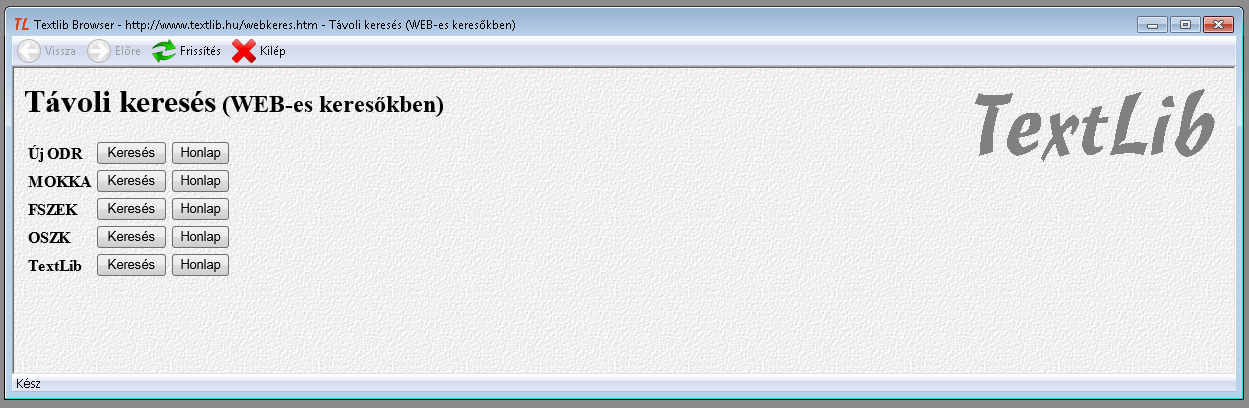
A kereséshez választhatjuk, hogy a Honlap nyomógombbal átlépünk az intézmény honlapjára, vagy a Keresés gombbal azonnal az intézmény web OPAC-jába. "Idegen" könyvtári katalógus az Új ODR, a MOKKA, a FSZEK és az OSZK. Bármelyiket is választjuk, a művelet innentől nem írható le általánosan, hiszen a web OPAC-ok különböznek, a kereséshez és a rekordok letöltéséhez ismerni kell a kiválasztott weblap kezelését. Általánosságban annyi mondható, hogy a letöltéshez felajánlott változatok közül a bináris (nem tagged!) Hunmarcot válasszuk, kerüljük a txt, html és xml formátumot, kódkészletnek pedig a diakritikus jelek mindegyikét ábrázolni képes UTF-8 vagy Ansel a megfelelő.
A TextLib itt lehetőséget ad a letöltött Hunmarc állomány tartalmának áttekintésére és formai helyességének ellenőrzésére.
A TextLib nyomógomb eltér az eddigiektől, az a web OPAC-ot működtető textlibes könyvtárak közös kereső felületére visz. Ezt a két félből összeollózott ábra mutatja:
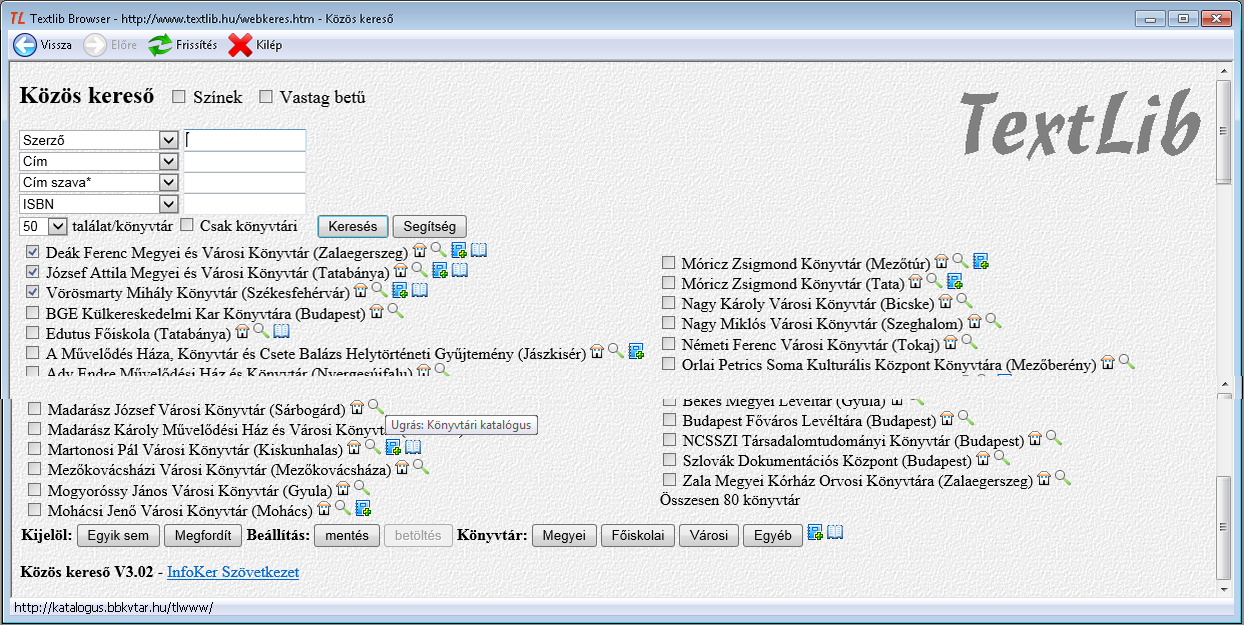
A keresésbe bevonandó könyvtárakat az intézmény neve előtti jelölőnégyzetbe kattintással, vagy az ablak alján a csoportos megjelölés nyomógombjait használva választhatjuk ki. A kereséshez négy mező áll rendelkezésre, ezeknek a tartalma egy-egy legördülő menüben változtatható. Ha több mezőt töltünk ki, akkor azok között a program automatikusan és megváltoztathatatlanul ÉS kapcsolatot létesít.
A keresés eredményét egy könyvtárak szerinti listában és egy összesített listában tekinthetjük át. A zöld lefelé mutató nyilacskával kezdeményezhetjük a rekordok letöltését.
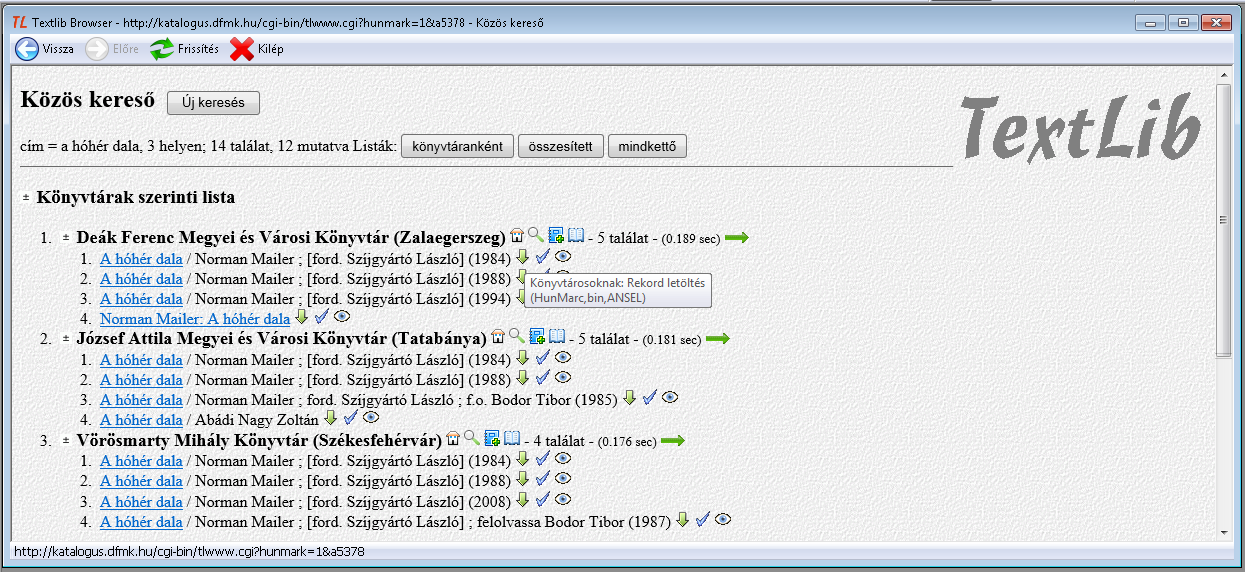
A távoli webes keresés eredménye a keresés természetéből adódóan sok találat is lehet. De még ha így is van, a talált rekordokat a saját TextLib adatbázisunkba csak egyesével tölthetjük be. Ez egy lényeges eltérés a Távoli (z39.50+tlwww) működéséhez képest.
A távoli keresés ebben a változatában is igaz, hogy a textlibes könyvtárakban többkötetes könyvek keresésekor, illetve analitikusan feltárt kötetek keresésekor többféleképpen járhatunk el, attól függően, hogy a többkötetes összes kötetére vagy csak valamelyikére, illetve az analitikák mindegyikére vagy csak valamelyikére van szükségünk:
- A közös adatot keresve eredményül kapjuk a közös adatot és külön kérés nélkül az összes kötetet, továbbá valamennyi kötet összes analitikáját, ha van.
- Valamelyik kötetet keresve csak azt a kötetet kapjuk, továbbá külön kérés nélkül az összes analitikáját, ha van.
- Valamelyik analitikát keresve csak azt az analitikát kapjuk.
2. Online Hunmarc import
A modul segítségével megtekinthetjük egy Hunmarc fájl (pl. a Kellóból letöltött) tartalmát, kereshetünk a rekordok között, és a kiválasztottakat egyesével vagy csoportosan a TextLib adatbázisba tölthetjük.
2.1. A modul indítása
A modul több helyről is indítható.
- A főmenü Bevitel / Hunmarc menüpontjából
- A könyv, az audiovizuális dokumentum, a térkép, a kotta, a szabadalom, a program dokumentumtípus különböző bibliográfiai szintű rekordjai beviteli ablakának menüjéből a Másik / minta Hunmarcból menüpontból.
- A bibliográfiai rekord módosító ablakból, az ablak lokális menüjében (Shift+F10) található Minta Hunmarcból menüponttal.
- A modul automatikusan elindul, ha a Keresés - Távoli (z39.50+tlwww) menüpontban indított keresés eredményes.
- A modul automatikusan elindul, ha a Keresés - Távoli (webes) menüpontban indított keresés eredményes.
- A modul automatikusan elindul, ha a TextLib munkaasztalra ráejtünk egy egérrel korábban megfogott Hunmarc fájlt.
A fent felsorolt menüpontok valamelyikének kiválasztása vagy az eredményes keresés után megjelenik a modul ablaka, ami az indulás módjától függően Hunmarc import vagy Távoli keresés nevű lehet. Menüből választva a modul ablaka üres lesz, a keresés végén vagy az ejtés után pedig már a találatok láthatók benne.
2.2. A modul képernyője
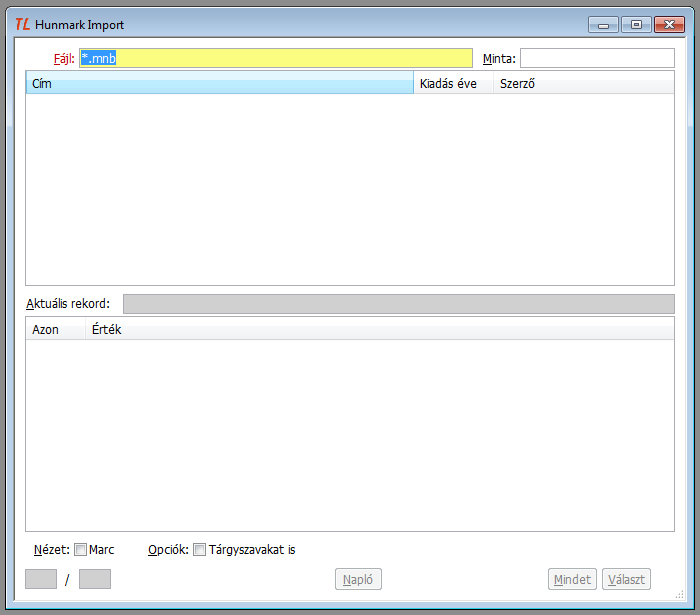
2.3. A modul használata
2.3.1. A fájlnév megadása
Ha az elindítás előbb felsorolt módozatai közül nem olyat választottunk, amelyik a modul automatikus indulásával jár, akkor először természetesen a feldolgozandó Hunmarc fájl nevét kell megadnunk. Az ablakban a Fájl mező az aktuális, ide írjuk be a fájl nevét az elérési úttal együtt. Használhatjuk a '*' karaktert is a fájl nevében, ez esetben tallózással választhatjuk ki a megfelelőt. Pl: KB530022.MNB, *.MNB, C:\sajat\*.mnb2.3.2. A fájl feldolgozása
Ettől a mozzanattól kezdve azonosan zajlik a fájlból és az online keresésből szerzett Hunmarc rekordok feldolgozása. A program értelmezi a Hunmarc rekordokat, és ezzel kapcsolatos adatokat ír ki a modul ablakába.2.3.3. Az import ablak mezői
- Ha keresésből érkeztünk, akkor a Fájl mező helyén a keresésről szóló információkat láthatjuk: a találatokat küldő könyvtár nevét és a keresési szempontokat.
- A Minta a találatok közötti keresésre szolgál. Az ide beírt szöveget keresi a program, és csak azokat a rekordokat tartja meg, amelyekben a Minta valahol előfordul. A Minta csak akkor működik, ha már az ablak kitöltődött, nem alkalmas a Fájl mezőben megadott Hunmarc állomány előzetes szűrésére.
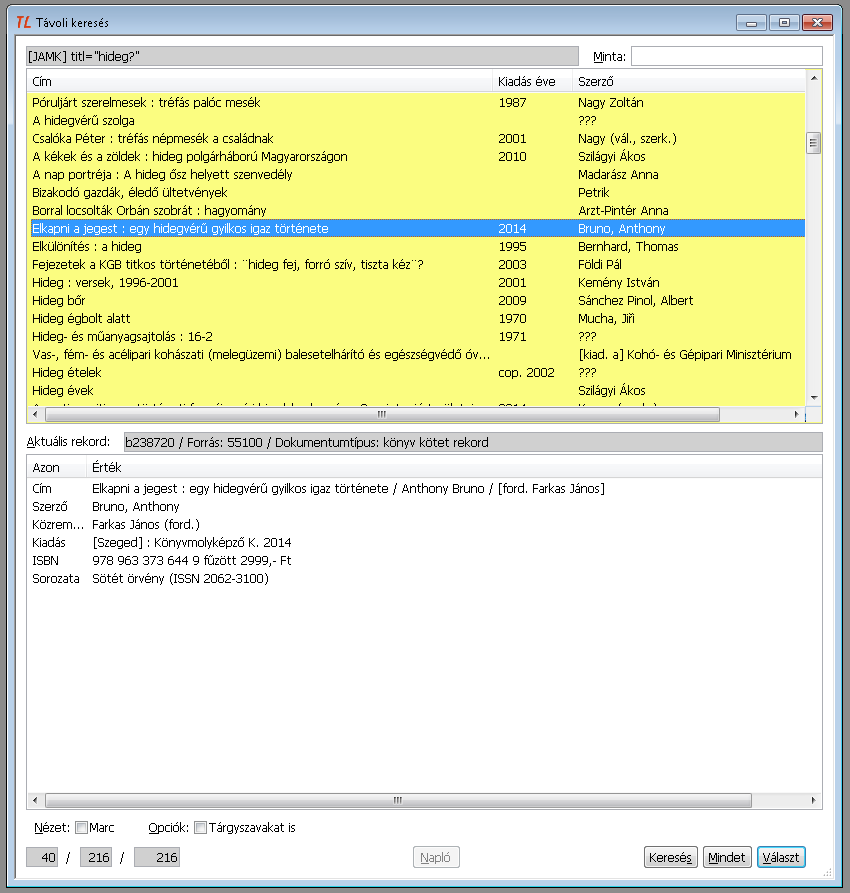
- Felső táblázat - A Cím - Kiadás éve - Szerző táblázatban a beolvasott rekordokat
láthatjuk egy-egy sorban. Bármelyik soron jobb egérgombbal kattintva egy helyzetérzékeny
menüt kapunk.
7. ábra: A helyzetérzékeny menü
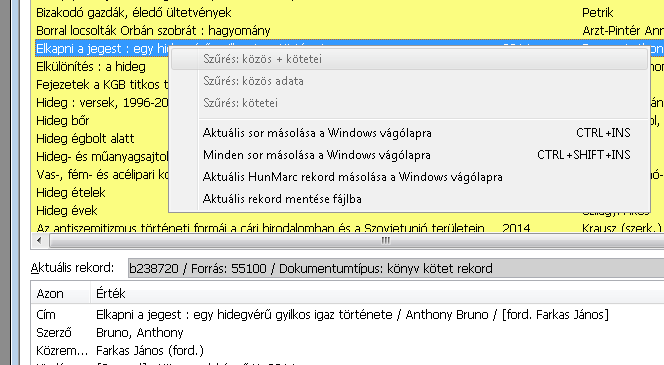
- Alsó táblázat - Azt a rekordot, amelyen a fénycsík áll, az ablak alsó felét elfoglaló Azon - Érték táblázat mutatja részletesen.
- Alatta a Nézet befolyásolja, hogy a rekordot címkés formátumban vagy Hunmarc formátumban látjuk. A rekord tartalmát a Hunmarc formátum mutatja teljes egészében, ezért ez alkalmasabb annak megítélésére, hogy a rekord valóban az-e és olyan minőségű, amelyet betölteni szeretnénk.
- Aktuális rekord - A két nagy táblázat közötti Aktuális rekord mező szintén segít a rekord alkalmasságának kérdésében dönteni. Itt a rekord eredeti azonosítója és a forrás azonosítója után a dokumentumtípus íródik ki. Ez a kiírás eldönti, hogy a TextLibbe töltve milyen dokumentumtípus, melyik bibliográfiai szintjéhez tartozó rekord jön létre. Előfordulhat, hogy ez a kiírás a várakozásainknak nem felel meg, mert a program pl. közös adat helyett kötetnek vagy fordítva állapítja meg a bibliográfiai szintet. Nincs lehetőség a változtatásra, az lesz a rekord, ami a dokumentumtípusban van.
- Az Opciók megengedi, hogy az érkező rekord tárgyszavakkal együtt, vagy ha saját tárgyszórendszerünk van, akkor nélkülük épüljön be az adatbázisunkba.
- Rekordszámok - A '/' jelekkel tagolt három szám azt mutatja, hogy hányadik rekordot látjuk az összes beolvasott közül, és az hogyan viszonyul az összes találathoz vagy a fájl rekordjainak a számához. Előfordulhat, hogy memóriakorlátok miatt nem olvasható be az összes rekord.
Végül a nyomógombok.
- A Napló nyomógomb akkor válik aktívvá, ha már az import közben vagyunk, amikor már elkezdődik a kiválasztott rekord betöltődése a TextLibbe.
- A Keresés gombbal visszajutunk a Keresés - Távoli (z39.50+tlwww) ablakba.
- A Mindet gomb lehetőséget ad arra, hogy a megtalált rekordokat egy gyors művelettel
egyszerre, megszakítás nélkül töltsük az adatbázisunkba. A munka folytatásáról
ebben a pontban olvashatunk.
A betöltés során a program minden egyes bibliográfiai rekordot és a besorolási rekordokat is összehasonlítja a saját adatbázisban találhatókkal, és egy részletesen kidolgozott szabályrendszer alapján dönti el, hogy az érkező rekord azonos-e egy már meglévővel. Azonosság esetén a meglévő rekord kiegészülhet, esetleg módosulhat az éppen érkező adataival, különbözőség esetén pedig az érkező újként kerül a saját adatbázisba.
- A Választ gombbal egyesével, szoros ellenőrzés mellett tölthetjük be a megtalált
rekordokat. Ezen az úton importálva láthatjuk az imént leírt összehasonlítások
eredményét olyankor, ha a TextLib az érkező rekordot egy már meglévővel azonosnak
ítéli. Ilyenkor megadja a beavatkozás lehetőségét is, dönthetünk arról, hogy az
azonosnak vélt vagy ténylegesen azonos rekordok egyesüljenek az importban, vagy az
érkező rekord mindenképpen újként kerüljön az adatbázisunkba.
A gomb megnyomásakor a program a saját adatbázis alapján az érkező rekordhoz hasonlókból listát készít és még a megmutatása előtt felhívja a figyelmet a tennivalóra.
8. ábra: Döntés a Választ megnyomása után
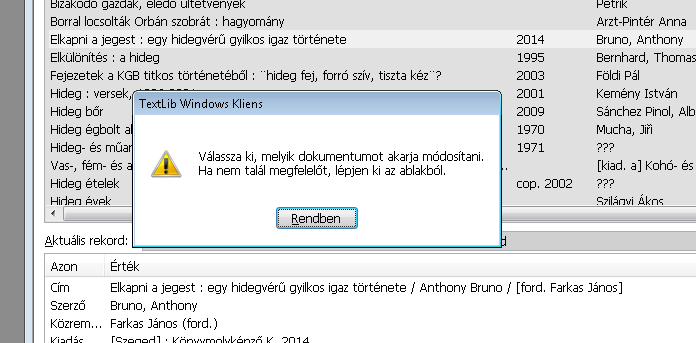
Látva a saját rekordjaink listáját, az előző ábra felszólításának megfelelően a Választ gombbal a meglévő rekordot módosíthatjuk, a Kiléppel pedig az érkezőt újként vihetjük be. Vigyázat! A saját rekordnak az érkezővel azonos címe nem jelent azonos bibliográfiai rekordot! A döntés előtt a biztonság kedvéért Ablakosan megnézhetjük a saját rekodunkat.
9. ábra: A hasonlók listája
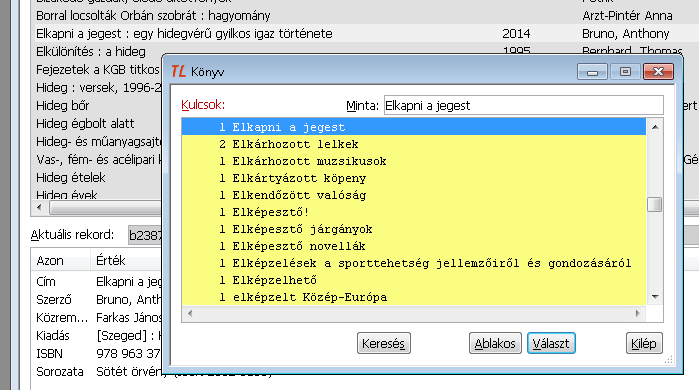
Amennyiben a program a besorolási rekordok (személyek, testületek, rendezbények stb.) feldolgozása közben nem tud dönteni az érkező és a meglévő azonosságáról, szintén megáll. A mechanizmus pedig azonos az előbbivel: Választ a választott módosítását eredményezi, a kilépéssel pedig új besorolási rekord bevitelét érjük el.
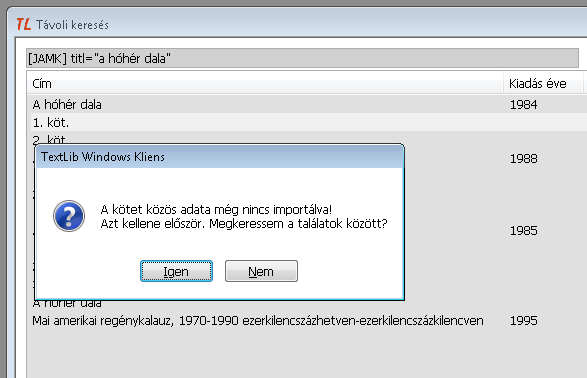
A program üzenetekkel segíti az összetartozó dokumentumok importját. A többkötetesek közös adatának és köteteinek, illetve a kötet és az analitikáinak a bevitele közben érkező üzenetek segítenek abban, hogy az összetartozók minden eleme bekerülhessen az adatbázisunkba. Ez akkor lehetséges, ha már a keresés eredményében megtalálható a többkötetesek összes rekordja, illetve a kötet-analitika csoport összes rekordja. Ennek pedig a korábban leírtaknak megfelelően a feltétele, hogy a kereséshez kiválasztott könyvtár textlibes könyvtár legyen.
10. ábra: A többkötetesek bevitelének támogatása
Az import a betöltött rekord ablakának megmutatásával fejeződik be. Azonnal módunk van a rekord javítására, kiegészítésére, példány adatokkal való ellátására.
Ha a felső táblázatban látható rekordok valamelyikét már betöltöttük, akkor a sor elejére egy '+' jel kerül.
A feldolgozés során létrejött rekordokat a program egy Hunmarc import rekordok nevű találati halmazba gyűjti, így adva lehetőséget további javításra, módosításra, kiegészítésre.
2.3.4. TextLib kötegelt Hunmarc import
Ebbe az ablakba akkor jutunk, ha a keresés eredményét áttekintve, a Mindet gombot megnyomva, egyszerre szeretnénk az összes megtalált rekordot a TextLibbe betölteni.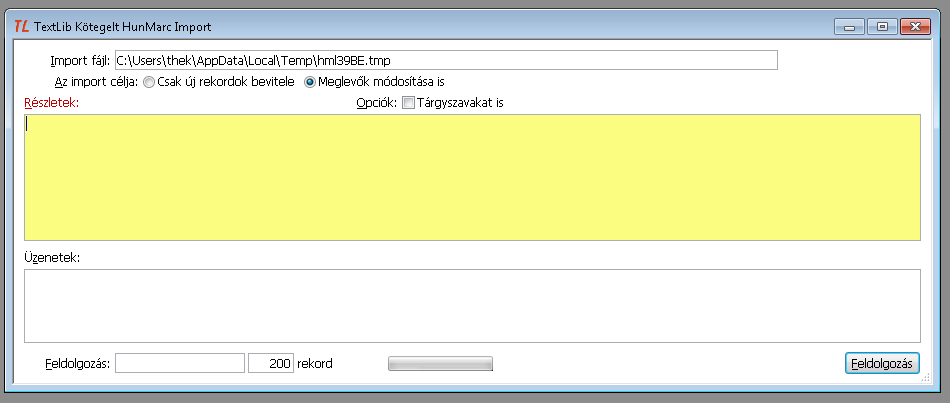
Mezők és beállítások
- Import fájl - A mezőbe - ha még nincs ott, vagy módosítani kívánjuk - beírhatjuk az importálandó fájl nevét.
- Az import célja
- Csak új rekordok bevitele - Ebben az esetben csak azok a rekordok kerülnek be az adatbázisunkba, amelyek az aprólékosan szabályozott összehasonlítási feltételek alapján új rekordoknak számítanak.
- Meglévők módosítása is - Ebben az esetben az import az új rekodok bevitele mellett a meglévőket is módosítja, amennyiben az aprólékosan szabályozott összehasonlítási feltételek alapján az érkező rekord az összehasonlítási feltételekben azonos egy meglévővel, de egyéb jellemzőiben eltér
- Az Opciók megengedi, hogy az érkező rekordok tárgyszavakkal együtt, vagy ha saját tárgyszórendszerünk van, akkor nélkülük épüljenek be az adatbázisunkba.
- Részletek - A művelet lefolyásának részleteit olvashatjuk, az érkező és a meglévő rekordok összehasonlításának eredményét.
- Üzenetek - Az egyes rekordok feldolgozásának részleteit olvashatjuk, döntően az ETO szétbontás eredményét.
- Feldolgozás - A számok a folyamat előrehaladásáról tájékoztatnak.
A munka a Feldolgozás nyomógombbal indítható.
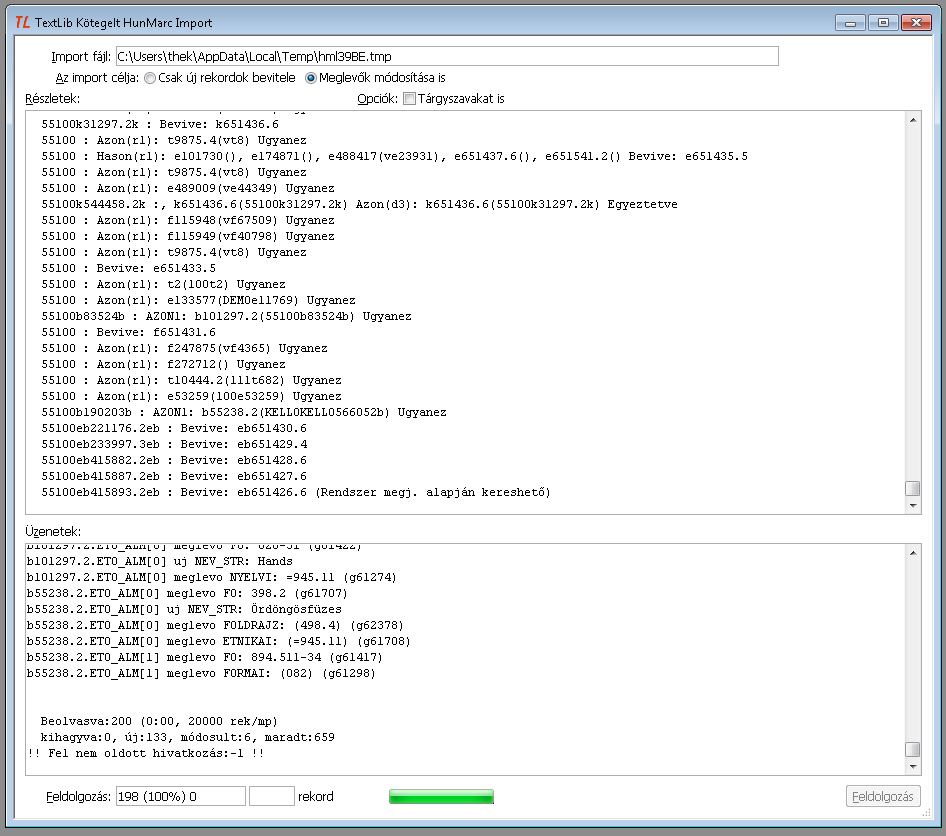
A feldolgozés során létrejött rekordokat a program egy Hunmarc import rekordok nevű találati halmazba gyűjti, így adva lehetőséget a kötegelt módban betöltött rekordok javítására, módosítására, kiegészítésére, példány adatokkal való ellátására.
Vissza: Kiegészitő programok TextLib honlap