Célja
A TextLib adatfájlok tömörítése, esetleges sérülések kijavítása. Normális esetben nem kell használni. Adatbázis sérülések után sem ezt kell elővenni, hanem naplózással kell helyreállítani az adatbázist. Ennek a programnak a használata csak a legvégső menedék lehet.
Különálló program, akkor használható, mikor a TextLib rendszer nem fut. Indítsuk el a programot a megfelelő paraméterekkel, ha nem tudjuk mik azok, akkor /? opcióval.
Paraméterek
Használat: DBF_PACK [paraméterek] [ds1 [ds2 ...]]
Paraméterek: (a többi paraméter: prgparam
Célja
A TextLib adatfájlok alapján ezzel a programmal tudjuk felépíteni az indexfájlokat. Ezekre a rekordok gyors megtalálásához van szükség.
Általában nincs szükség az indexfájlok újraépítésére, mivel a TextLib használata közben folyamatosan változnak. A következő esetekben lehet csak szükség erre a programra:
Különálló program, akkor használható, mikor a TextLib rendszer nem fut. Indítsuk el a programot a megfelelő paraméterekkel, ha nem tudjuk mik azok, akkor /? opcióval.
A program futása félbeszakítható, és a legközelebbi alkalommal folytatható. Akkor viszont ugyanezeket a paramétereket kell megadni, különben nem indul el. Ha paraméter nélkül is hívhatjuk ilyenkor, a megszakításkor érvényes paramétereket fogja használni.
NOVELL hálózat használata esetén az adatbázis indexelése egyszerre több gépről is végezhető. Ez az indexeléshez szükséges időt természetesen jelentős mértékben csökkenti. Természetesen minden gépen más-más indexset-eket kell indexelni.
Célja
A TextLib indító BATCH-ekben használjuk, normális esetben nincs szükség a program ettől eltérő használatára.
NAPLO funkció [/funkció] [paraméterek]
Funkció:
| paraméter | Ell | Letr | Ment | Tolt | List | Feltétel |
|---|---|---|---|---|---|---|
| /Letr | + | - | - | + | - | túl nagy a napló vagy új napló kell |
| /Ment | + | - | - | + | - | túl nagy a napló és nincs megadva /Letr, vagy menteni kell |
| /Tolt | + | - | - | - | - | megsérült az adatbázis |
| /LMT | + | - | - | - | - | /Letr, /Ment és /Tolt együtt |
| paraméter | Ell | Letr | Ment | Tolt | List | Magyarázat |
|---|---|---|---|---|---|---|
| /P<path> | + | + | + | + | + | path az adatbázis leírás kereséséhez: path>\TLM\DBDESCS.TLM (alapértelmezés: \TEXTLIB) |
| /D<path> | + | + | + | + | - | path az adatbázis kereséséhez (alapértelmezés: ha /P adott, akkor azonos, ha nem, akkor /P alapértelmezése) |
| /J<path> | - | - | - | + | + | path napló kereséshez (alapértelmezés: \TEXTLIB\MENT) |
| /A<path> | - | - | - | + | + | path régi (*.ANF) naplók kereséshez (alapértelmezés: /J szerint) |
| /M<path> | - | - | + | + | - | path adatbázis mentésnek (alapértelmezés: /J szerint) |
| /M2<path> | - | - | + | + | - | path biztonsági adatbázis mentés kereséshez (alapértelmezés: nincs) |
| /regiszt | - | - | + | - | - | csak mentés regisztrálás |
| /mozgat | - | - | - | + | - | sikeres adatbázis helyreállítás után nem másolja, hanem átrakja az adatbázist (/M<path> --> /D<path>) |
| /vanm2! | - | - | - | + | - | a biztonsági mentés létét jelzi, ha /M2 nincs megadva |
| /folyt | - | - | + | - | + | napló folytatás engedélyezése |
| /regi | - | - | - | + | + | régi (*.ANF) naplók használatának engedélyezése |
| /L<név> | + | + | + | + | - | LOG fájl neve (alapértelmezés: NAPLO.LOG, hely /D szerint) |
| /s<méret> | + | - | - | - | - | maximális napló fájl méret kByte-ban (alapértelmezés: 150 kByte, min: 0kbyte) |
| /Aigen | + | + | + | + | + | automatikus 'igen' minden kérdésre |
Hibakódok
Célja
A TextLib adatfájlokon végigmenve ellenőrzi a legfontosabb összefüggések meglétét, mezők helyességét, stb.
Használata
Különálló program, akkor használható, mikor a TextLib rendszer nem fut. Indítsuk el a programot a megfelelő paraméterekkel, ha nem tudjuk mik azok, akkor /? opcióval.
A program futása félbeszakítható, legközelebb folytatható. Akkor viszont ugyanezeket a paramétereket kell megadni, különben nem indul el. Folytatásnál paraméter nélkül is hívható; ilyenkor a megszakításkor érvényes paramétereket fogja használni.
DBCHK opciók
A //javit opció használata előtt célszerű az adatbázist menteni, a futást követően a DBCHK.LOG fájlból tájékozódni, hogy mely hibákat javította a program. Ezt követően célszerű egy újabb (csak //kolcs opció //javit opció nélkül) futtatással meggyőződni, arról, hogy mely hibák maradtak, azaz mely hibák javítása nem sikerült. Ezek javítása csak az adatbázis és a valóság egybevetése után, rendszergazdaként belépve, a megfelelő rekordok mezői egymással összhangban történő javításával lehetséges, és az adatbázis szerkezetének alapos ismeretét feltételezi. Ha nem 100 %-osan biztos abban, hogy mit kell tenni, inkább kérje az InfoKer segítségét!
Célja
A TextLib adatfájlokon végigmenve az összes rekord összes mezőjében lecserél egy rekord azonosítót egy másikra.
Használata
Különálló program, akkor használható, amikor a TextLib rendszer nem fut. Indítsuk el a programot a megfelelő paraméterekkel, ha nem tudjuk mik azok, akkor /? opcióval.
DREFCHG [miről mire | @fname} [/Hazon] [/teszt]
Ha nem az egész adatbázisra akarjuk ráereszteni a cserét, akkor be kell lépni a TextLibbe, ott előállítani a megfelelő halmazt, és elmenteni. Kilépve a TextLibből a DREFCHG-nek meg kell adni, kinek az elmentett halmazán dolgozzon (/Hazon - ahol 'azon' a dolgozó azonosítója)
t33.2 t3 t43.3 t3
DREFCHG @budapest.dat
Célja
A TextLib adatbázis rekordok listázása, mezők törlése, kitöltése, stb.
Használata
Különálló program, akkor használható, amikor a TextLib rendszer nem fut. Indítsuk el a programot a megfelelő paraméterekkel, ha nem tudjuk mik azok, akkor /? opcióval.
Hívási mód: DBRUN [param] [param] [...]
| /Ppath | path az adatbázis leírás kereséséhez. Def: \TEXTLIB |
|---|---|
| /Dpath | path az adatbázis kereséséhez. Def: /Ppath |
| /Rdref | rekordok tartalmát a dref.lst fájlba írja. |
| /Kdref | törli az adott datarefű rekordot - mindenképp |
| /K@fájl | törli a fájlban megadott rekordokat - mindenképp |
| /Xdref | törli az adott datarefű rekordot - ha lehet |
| /X@fájl | törli a fájlban megadott rekordokat - ha lehet |
| /Ffld:dref | törli a dref azonosítójú rekord fld mezőjét |
| /Ffld/rno:dref | törli a mező adott előfordulását |
| /Sfld:dref=dr | beállítja a dref azonosítójú rekord fld mezőjét |
| /Sfld/rno:dref=dr | beállítja a mező adott előfordulását |
| /Sfld1/rno1;fld2/rno2:dref=dr | almező beállítása rno == -1 jelenti az utolso ismetlodest |
| /Tdref | törli a dref azonosítójú rekord <törölt rekord> pointereit |
| //noindex | ROSSZ rekordok törléséhez. Ne törölje az indexeket |
| @fname | a paramétereket fájlból veszi |
A b7 rekord törlése, ha nem hivatkozik rá más rekord:
DBRUN /Xb7
DBRUN /K@torold.bat
DBRUN /F70:b7
DBRUN /Kb7
DBRUN /S70:b7=f4
Célja
Az adatbázisba szövegfájlból betölti a help rekordokat. A szövegfájl speciális formájú. A felújító lemezek tartalmazzák mindig az aktuéális helpeket, verzióváltás után érdemes ezeket mindig betölteni.
A program a \TEXTLIB\HELP könyvtárban található !
Használata
HELPIMP fájlnév HELPIMP @fájlnév
Utóbbi esetben a fájlban vannak felsorolva a betöltendő fájlok nevei, minden sorban egy.
Összes help betöltése
Az összes help betöltéséhez készítettünk egy batch fájlt (ALLHELP), a verzióváltás után ezzel érdemes betölteni a helpeket, ily módon:
CD \TEXTLIB\HELP ALLHELP.BAT
Funkciója
A leltározás előkészítése a TextLib adatbázisban. A leltározás indításának előfeltétele a program futtatása.
Használata
A programmal a TextLib adatbázisban lévő összes példányt vagy egy találati halmazba gyűjtött kiválaszott példányokat leltározandónak jelölhetünk. Az első esetben semmiféle előkészületre nincs szükség, a második esetben a találati halmazt a TextLibben kell előállítani majd elmenteni. Ezután a LELTELOK futtatásakor a mentést végző dolgozó belépési azonosítóját kell paraméterként megadni.
A program csak közvetlenül a TLSRV leállítása és egy adatbázis mentés (tl_ment) után futtatható. Futás után is azonnal menteni kell az adatbázist - ezt a várhatóan nagy mennyiségű példány rekord módosítás indokolja. A mentés után indítható újra a TLSRV.
LELTELOK.EXE futási ideje a könyvtár állományának nagyságával arányos, ezért nagyszámú példány esetén relative hosszú lehet. Az idő becsléshez támpontként szolgálhat az adatbázis újraindexelési ideje.
Paraméterek
LELTELOK paraméterek
A program általában nem igényel paramétereket. Ha nem az összes példányt kívánjuk leltározandónak jelölni vagy ha nem a szokásos adatbázis környezetben indítjuk, akkor azonban igen.
Megadható paraméterek:
Működése során a program a példány rekordokba bejegyzi, hogy leltározandó. Ha nem adunk meg halmazt, akkor az összesbe, ha megadnuk, akkor csak a halmazban szereplőkre. Ez a módszer használható pl. egy állomány leltározásához.
Kivételt képeznek, tehát nem leltározandók azok a példányok amelyek:
Sikeres futás után a program feljegyzi a "Könyvtárunk adatai" rekordba, hogy a leltár előkészítés megtörtént. A program gondoskodik arról is, hogy az így előállt adatbázis-állapotot menteni kelljen.
A program sikeres futása és a mentés után a TextLibben indítható a leltározás.
A leltározás előkészítése - a LELTELOK program lefutása - után a leltározás lezárásáig újabb leltározás nem indítható.
Célja
A program rendszerkarbantartási időben aktualizálja a késedelmi díjakat, hogy ne kelljen a rendszer futása közben a kölcsönző, visszavevő ill. hosszabbító modulokban az olvasó azonosítása után a tartozásainak aktualizálásával értékes on-line időt tölteni.
Működése
A program az összes olvasó végigjárásával azok valamennyi kölcsönzését elemzi, hogy nem képződött-e késedelmi tartozás, vagy nem változott-e egy már korábban létezett késedelmi tartozás összege. Ha szükséges, létrehozza ill. aktualizálja a tartozást, egyúttal az olvasó rekordján is átvezeti a változás(oka)t. Az olvasó rekordjában mindenképpen könyveli, a tartozások aktualizálásának megtörténtét (akkor is, ha nem képződött ill. nem változott késedelmi tartozás), hogy az olvasószolgálati modulok ne próbálják meg fölöslegesen aktualizálni a késedelmi tartozásokat.
Használata
Különálló program, akkor használható, mikor a TextLib rendszer nem fut. A programnak az általános program-paramétereken prgparam túl nincs(ennek) külön paramétere(i). Ha /? opcióval indítjuk, rövid ismertetést ad magáról.
Célszerű minden olyan könyvtárban használni, ahol többgépes rendszert üzemeltetnek és az olvasószolgálati forgalom jelentős.
Lehetséges alkalmazásai:
Az olvasószolgálati munka során nagy mennyiségben keletkeznek az egyes tranzakciókkal (kölcsönzés, előjegyzés, tartozás, felszólítás) kapcsolatos rekordok. Azt követően, hogy a kérdéses tranzakcióhoz tartozó valóságos folyamatok befejeződnek, a rekordok lezárttá válnak, további tárolásuk már csak az utólagos statisztikai feldolgozás céljából indokolt. Ezek megtörténte után ill. bizonyos idő elteltével a rekordok tárolására már egyáltalán nincs szükség. A rekordoknak az idők végezetéig való tárolása nem célszerű, hiszen bizonyos idő elteltével az adatbázis nagyobbik részét már ilyen rekordok teszik ki, így az adatbázis karbantartásával (mentésével, ellenőrzésével, indexelésével, stb.) kapcsolatos feladatok időigénye értelmetlenül nagyra nő.
Az olvasószolgálattal kapcsolatos, fölöslegessé vált, nagy mennyiségű, régi rekordtól a PUCOL program segítségével lehet megszabadulni. A programot off-line módon, azaz olyankor lehet futtatni, amikor a TextLib rendszert éppen nem használjuk. A program egyetlen paramétere az a dátum, amely előtti rekordok törlését kérjük:
PUCOL dátum
(A dátum megadása ÉÉÉÉHHNN alakban lehetséges, azaz az évszámot négy, a hónapot és a napot 2-2 jegy hosszban kell megadni.)
A program az egyes rekordok közül az alábbiakat törli:
| kölcsönzés rekordok: a paraméterben megadott dátum előtt megtörtént a visszavétel, és sem késedelmi, sem térítési díj típusú rendezetlen tartozás nem kötődik a kölcsönzéshez. |
|---|
| előjegyzés rekordok: - a soha ki nem elégített előjegyzések közül | azokat törli, amelyek a paraméterben megadott dátum előtt elévültek;
| a kielégített előjegyzések közül azokat törli, amelyeknél az előjegyzés kielégítésére használt példány olvasó számára történt félretételének dátuma a megadott dátum előtti. |
| tartozás rekordok: csak a rendezett tartozásokat törli, ezek közül is csak azokat, amelyek rendezése a megadott dátum előtt történt meg. |
| felszólítás rekordok: azokat a felszólításokat törli, amelyeken szereplő egyetlen tétel sem aktuális már, azaz minden a felszólításban érintett kölcsönzött példány vissza lett véve, ill. minden tartozás rendezve lett, és a felszólító levél dátuma a megadott dátum előtti. |
Célja
Ha az adatbázist más könyvtárnak akarjuk átadni, ki kell irtani belőle a felesleges rekordokat, a megmaradókat pedig megfelelően módosítani kell.
Használata
Különálló program, akkor használható, mikor a TextLib rendszer nem fut. Indítsuk el a programot a megfelelő paraméterekkel, ha nem tudjuk mik azok, akkor /? opcióval.
ATADAS opciók
LOG fájl
A program a futás végén összefoglalót ír az ATADAS.LOG fájlba, hogy milyen rekordokat törölt, és miket módosított.
Rekordok
A program a következő rekordokat irtja ki:
A KÖNYVTÁR adatait leíró rekordból kitörli csaknem az összes mezőt, mivel azok a könyvtárra jellemzőek. A rekord maga nem törölhető, nélküle nem indulna el a TextLib.
A megmaradó rekordokban kitölti az IMPORT_AZON mezőt. Ha az átadott adatbázisba később az eredeti adatbázisból akarunk importálni, ez nagyon leegyszerűsíti majd a rekordok azonosítását.
Indexfájlok hibátlanságánal ellenőrzéséhez. Akkor érdemes foglalkozni vele, ha az indexfájlok gyanússá válnak.
Célja
TextLib rekordok listázására alkalmas.
Használata
Különálló program, akkor használható, mikor a TextLib rendszer nem fut. Indítsuk el a programot a megfelelő paraméterekkel, ha nem tudjuk mik azok, akkor /? opcióval.
DBF_LST [/Ppath] [/Dpath] [/Nx] [Rdref] [/K] [/F|n1..|f1..]
Célja
TextLib indexfájlok listázása
Használata
Különálló program, akkor használható, mikor a TextLib rendszer nem fut. Indítsuk el a programot a megfelelő paraméterekkel, ha nem tudjuk mik azok, akkor /? opcióval.
NDX_LST [/r] [/k] n|fname
Célja
A TextLib adatfájlokon végigmenve az összes rekord összes mezőjében keresi az adott rekord azonosítókat.
Használata
Különálló program, akkor használható, amikor a TextLib rendszer nem fut. Indítsuk el a programot a megfelelő paraméterekkel, ha nem tudjuk mik azok, akkor /? opcióval.
Használat: FINDDREF mit | @fájl [/Hazon [/teszt]
Ha nem az egész adatbázisra akarjuk ráereszteni a keresést, akkor be kell lépni a TextLibbe, ott előállítani a megfelelő halmazt, és elmenteni. Kilépve a TextLibből a FINDDREF-nek meg kell adni, kinek az elmentett halmazán dolgozzon (/Hazon - ahol 'azon' a dolgozó azonosítója)
Célja
A TL_KULD program segítségével egy találati halmazt (egy dolgozó elmentett halmazát) exportálhatjuk. A program egy szövegfájlt készít, amit általában egy másik adatbázisba töltünk a TL_VESZ program segítségével. Természetesen ettől eltérő felhasználása is lehetséges.
Használata
A TextLibben gyűjtsük össze egy találati halmazba azokat a rekordokat, amiket exportálni akarunk. Amikor ez megvan, mentsük el ezt a halmaz az eLment gomb segítségével (Vigyázat! Mindig az aktuális elmentett halmazt tudjuk exportálni), majd lépjünk ki a TextLibből.
A TL_KULD program indításakor egyetlen paramétert kötelező megadni, annak a dolgozónak az azonosítóját, akinek az elmentett halmazát exportálni akarjuk (általában a saját azonosítónkat).
Megadhatunk még más paramétereket is (lásd: Paraméterek), de erre elég ritkán van szükség.
Paraméterek
TL_KULD dolgozo [outfájl] [opcio] [opcio] ...
A program egy konfigurációs fájlból tudja, hogy milyen rekordot hogyan kell kiírnia az output fájlba. Abban van leírva, hogy mely rekordokat kell egyáltalán kiírni, és mely rekordnak mely mezőit. Ezt a fájlt először az aktuális könyvtárban keresi a program, ha itt nem találja, akkor megnézi ott is, ahol a TL_KULD.EXE van.
A konfigurációs fájlban utasításokat használhatunk az export módjának és tartalmának szabályozására. Az alábbiakban egy lehetséges konfigurációs fájl olvasható, benne kommentként az utasítások magyarázata.
TextLib Export leiro file - InfoKer 1995 # TextLib Export leiro file - példa # # Kodkeszlet: CWI - ez lehet csak jelenleg # Hivatkozott:I|N|X - hivatkozott rekordok kiirasa: I|N # X: csak azokat a hivatkozottakat irja ki, aminek van leirasa a cfg-ben # Cel:B|M|T - export célja: Bevitel, Módosítás, Törlés Kodkeszlet:CWI Hivatkozott:N Cel:M # &r - rekord tipus ; &d - datafile # /MIND - minden mezo, /RENDSZER - rendszer mezok &r DOKUMENTUM /MIND /RENDSZER
Output fájl
A program outputja TextLib Csere formátumú. Ez egy szövegfájl, amiben az exportált rekordokon kívül a küldéssel kapcsolat információk is megtalálhatók (Hány rekord van a fájlban, ki küldte, mikor, stb).
A TextLib Csere formátum a CSERE.TXT fájlban van részletesen leírva.
LOG fájl
Minden küldésnél a program készít egy ún. LOG fájlt, amibe mindenféle információkat kiír. Pl:
A LOG fájl részletes leírása a KULDLOG.TXT fájlban található.
História fájl
A program készít egy história fájlt is, amiben az összes export fontosabb adatai fel vannak sorolva (Ki, mikor exportált, hány rekordos találati halmazból hány rekord került kiírásra és hány hivatkozott rekord volt).
A História fájl szerkezete igen egyszerű, magától értetődik. Abban a könyvtárban található, ahol a TL_KULD program, a neve pedig TL_KULD.HST
Hibaüzenetek
- Nincs adatbázis azonosító
A könyvtár adatai közt be kell állítani egy adatbási azonosítót. Erre
azért van szükség, hogy a különböző adatbázisból származó rekordok
megkülönböztethetők legyenek. Ellenkező esetben két külön adatbázisból
kapott b3 azonosítójú rekordot megegyezőnek tekintene a program.
Hibakódok
A program futása után beállítja a DOS-ban az ERRORLEVEL változót. Ebből tudhatjuk, hogy milyen hibával ért véget a program.
0 - minden rendben volt ?? - hibakód
A program sorra veszi a találati halmaz rekordjait, és megvizsgálja a bennük szereplő hivatkozásokat is. Ha ki kell írnia a hivatkozott rekordokat is, akkor azokat a rekord elé rakja ki. Természetesen a többszörös mélységű hivatkozásokat is kezeli. A rekordnak azokat a mezőit, amik olyan rekordra hivatkoznak, amit nem kell kiírnia, nem írja ki. Azaz: ha egy kapcsolódó mező az A, B és C rekordokra mutató pointereket tartalmaz, de a B rekordokat nem kell a programnak kiírnia, akkor a mezőnek csak az A és C rekordokra mutató értékei kerülnek ki az output fájlba.
A rekord almezőit szintén a rekord elé írja is. Az almezőket 1-től indulva sorszámozza. Ez azért előnyös, mert így az almezők is egyedi 'rekord' azonosítót kapnak.
Lásd még
A DBSTRUCT program segítségével tudhatjuk meg, hogy az adatbázisban milyen adatfájlok, rekordtípusok és mezők vannak.
Várható fejlesztések
-- Más kódkészlet (pl: 852-es) használata
Célja
A TL_VESZ program segítségével egy TextLib csere formátumú fájlban levő rekordokat tudjuk a TextLib adatbázisunkba betölteni.
Használata
A program indításakor egyetlen paramétert kötelező megadni, annak a fájlnak a nevét, amiben az importálandó rekordok vannak. A fájl kiterjesztését nem kötelező megadni, ha az .TCS
Megadhatunk még más paramétereket is (lásd: Paraméterek), de erre elég ritkán van szükség.
Paraméterek
TL_VESZ infile [opció] [opció] ...
A program egy konfigurációs fájlból tudja, hogy milyen rekordot hogyan kell kezelnie. Abban van leírva, hogy mely rekordokat kell eldobnia, újként felvennie, módosítani. Az egyes rekordok kezelésének módja is itt van megadva (mely mezővel mit kell csinálni). Ezt a fájlt először az aktuális könyvtárban keresi a program, ha itt nem találja, akkor megnézi ott is, ahol a TL_VESZ.EXE van.
Az Import leíró fájl (.cfg) részletes leírása itt található.
Input fájl
A program inputja TextLib Csere formátumú. Ez egy szövegfájl, amiben az exportált rekordokon kívül a küldéssel kapcsolat információk is találhatók (Hány rekord van a fájlban, ki küldte, mikor, stb).
A TextLib Csere formátum a CSERE.txt fájlban van részletesen leírva.
LOG fájl
Minden import alkalmával a program készít egy ún. LOG fájlt, amibe mindenféle információkat kiír. Pl:
História fájl
A program készít egy história fájlt is, amiben az összes import fontosabb adatai fel vannak sorolva (Mikor mennyit importáltunk).
A História fájl felépítése magától értetődő, TL_VESZ.HST néven abban a könyvtárban találjuk, ahol a TL_VESZ program is van.
Rekordba írt rendszer megjegyzések
Az import során a program több rekord rendszer megjegyzés mezőjébe is ír szövegeket. Ezek kivétel nélkül a # karakterrel kezdődnek. Egy import után a LOG fájl megnézése után ezeket a rekordokat érdemes lekeresni, és megnézni.
A program futása után beállítja a DOS-ban az ERRORLEVEL változót. Ebből tudhatjuk, hogy milyen hibával ért véget a program.
0 - minden rendben volt ?? - hibakód
A program beolvassa az input fájlban található rekordokat. Azokat, amikkel nem kell semmit csinálnia (az import leíró fájlból tudja) eldobja. A többit pedig a megadott utasítások szerint feldolgozza. Menet közben számolja, hogy hány új rekordot vett fel, hányat módosított, és hányat hagyott érintetlenül.
A problémás rekordokat kétféle módon kezeli:
A DBSTRUCT program segítségével tudhatjuk meg, hogy az adatbázisban milyen adatfájlok, rekordtípusok és mezők vannak.
Várható fejlesztések
Más kódkészlet (pl: 852-es) használata
Célja
A HM_KULD program segítségével egy találati halmazt (egy dolgozó elmentett halmazát) exportálhatjuk Hunmarc formátumban.
Használata
A TextLibben gyűjtsük össze egy találati halmazba azokat a rekordokat, amiket exportálni akarunk. Amikor ez megvan, mentsük el ezt a halmazt az eLment gomb segítségével majd lépjünk ki a TextLibből.
Figyelem!
Több elmentett halmazból mindig az aktuálisat tudjuk exportálni.
Figyelem! Az export végrehajtásához a dokumentum típusú rekordokat (pl. könyv kötet, audiovizuális kötet, disszertáció, stb.) szükséges és elégséges a találati halmazba összegyűjteni. A dokumentum által hivatkozott személyek, testületek, földrajzi nevek, sorozati adatok, stb. automatikusan bekerülnek a HunMarc rekordba.
A HM_KULD program indításakor egyetlen paramétert kötelező megadni, annak a dolgozónak az azonosítóját, akinek az elmentett halmazát exportálni akarjuk (általában a saját azonosítónkat).
Megadhatunk még más paramétereket is (lásd: Paraméterek), de erre elég ritkán van szükség.
Paraméterek
HM_KULD dolgozo [outfile] [opcio [opcio] ...
A program egy konfigurációs fájlból tudja, hogy milyen rekordot hogyan kell kiírnia az output fájlba. Abban van leírva, hogy mely rekordokat kell egyáltalán kiírni, és mely rekordnak mely mezőit. Ezt a fájlt először az aktuális könyvtárban keresi a program, ha itt nem találja, akkor megnézi ott is, ahol a HM_KULD.EXE van.
A konfigurációs fájlban utasításokat használhatunk az export módjának és tartalmának szabályozására. Az alábbiakban egy lehetséges konfigurációs fájl olvasható, benne kommentként az utasítások magyarázata.
TextLib Export leiro file - InfoKer 1995 # # Ebben a minta cfg-ben vannak felsorolva azok az utasítások, # amelyek az éles export cfg-ben használhatók. # Az utasításokat egymásnak ellentmondó módon is meg lehet # adni, az ebből származó problémákat a program egy erősorrend alkakalmazásával # zárja ki. Pl. a 'MokkaExport' akkor is exportálja a példányolat, ha # a 'PeldanytIs' értéke 'n'. # InfoKer 2025 # Az utasítások: # Kodkeszlet:Utf-8 # Hivatkozott: 'i/n' # A hivatkozottak a Hunmarcnál a közös-kötet-analitika # hivatkozást jelenti # Szabvanytalan: 'i/n' # A Hunmarcban nem szabványos, de létező mezők exportja # PeldanytIs: 'i/n' # Kell-e egyáltalán példányt exportálni. Ha nem, akkor tök # mindegy, hogy mi van a többi példányos varázsigében. Ha # viszont igen, akkor mindenképp kell SajatPeldany és/vagy # KszrPeldany # SajatPld: 'i/n' # Exportálni kell a saját példányokat. Saját példány kszr # könyvtárban az ellátó példány, nem kszr-ben minden. Ha kszr # könyvtár valamelyik településéről exportálunk, akkor ennek a # kiválasztott könyvtárnak a példányai is sajátok, megadás mélkül is. # KszrPeldany: 'i/n' # Ha kellenek a kszr települési példányok is. # DefPeldany:'nn,x12345' # a példány mezősorszáma, amelyikben egy részlegnek (könyvtár, # raktár, állomány) a datarefje van, azé, amelyik részlegnek # a példányait exportálni kell. # Ha SajatPeldany és KszrPeldany is meg van adva, akkor ez a # definíció csak a kszr könyvtárak példányaira vonatkozik. # Specpeldany: 'i/n' # Ha MarcTipus üres, akkor a példányok specpéldányként mennek # ki a kibővített 852-es mezőbe # MokkaExport: 'i/n' # Példányok mindenképpen mennek a szűk 852-be és 876-ba. # CorvinaPeldany: 'i/n' # Abazon: 'i/n' # RecAzon: 'i/n' # Adatátadáshoz. Azokba a mezőkbe, amelyekben ezeknek a rekordtípusoknak # az adatai vannak, bekerül egy almezőbe a rekordazonosítójuk is: # ALKOTO_rt, TESTULET_rt, TEZAURUSZ_rt, FOLDRAJZ_rt, IDOSZAM_ft # Miszje: 'i/n' # MarcTipus: '21' ha MARC21 export kell Kodkeszlet:Utf-8 MokkaExport:i Hivatkozott:i Szabvanytalan:n PeldanytIs:i SajatPld:i Specpeldany:n Abazon:i &r DOKUMENTUM /MIND &r PELDANY /MIND &r CIMADAT /MIND &r PARHCADAT /MIND &r KIADAS /MIND &r NYOMTATAS /MIND &r IDOSZAM /MIND &r MU /MIND &r ALKOTO /MIND &r TESTULET /MIND &r FOLDRAJZ /MIND &r KOZREMUKODO /MIND &r SOROZATLEIRAS /MIND &r SOROZAT /MIND &r ETO_ALM /MIND &r TEZAURUSZ /MIND &r WWW /MIND &r MELLEKLET /MIND &r ALL /MIND &r CEG /MIND &r RAKTAR /MIND &r FIOK /MIND &r DOK_OSZT /MIND
Figyelem!
Az output fájl karakterkészletét is az export leíró fájlban lehet megadni.
Ha ext nem tesszük, akkor az MNB CD (ez a 852-es) karakterkészletét használja
a program.
Output fájl
A program outputja Hunmarc formátumú, a mezőkbe került szövegek kódkészlete az export leíró fájlban megadottnak felel meg. A TextLib karaktereket a program <HM_CHAR> szerint konvertálja a HunMarc szövegállományba.
Figyelem!
Amennyiben az output fájl karakterkészletének a CWI-t adta meg, tartalmi
veszteséggel kell számolnia, ugyanis a TextLibben értelmezett, de CWI-ben nem
értelmezett karakterek a konvertálás során elvesznek.
A TextLib és HunMarc rekordok közötti mező-mező megfeleltetést <HM_MEZO>
írja le.
LOG fájl
Minden küldésnél készít a program egy ún. LOG fájlt, amibe mindenféle információkat kiír. Pl:
História fájl
A program készít egy história fájlt is, amiben az összes export fontosabb adatai fel vannak sorolva (Ki, mikor exportált, hány rekordos találati halmazból hány rekord került kiírásra és hány hivatkozott rekord volt).
A História fájl szerkezete igen egyszerű, magától értetődik. Abban a könyvtárban található, ahol a HM_KULD program, a neve pedig HM_KULD.HST
Hibakódok
A program futása után beállítja a DOS-ban az ERRORLEVEL változót. Ebből tudhatjuk, hogy milyen hibával ért véget a program.
0 - minden rendben volt ?? - hibakód
A program sorra veszi a találati halmaz rekordjait, és a rekord mezőiből, valamint a hivatkozott rekordok mezőiből elkészít egy Hunmarc rekordot.
Lásd még
A DBSTRUCT program segítségével tudhatjuk meg, hogy az adatbázisban milyen adatfájlok, rekordtípusok és mezők vannak.
Célja
A HM_VESZ program segítségével egy HunMarc formátumú fájlban levő rekordokat tudunk a TextLib adatbázisunkba importálni.
Használata
A program használatához egy paramétert kötelező megadni: az importálandó HunMarc rekordokat tartalmazó állomány nevét. Megadhatunk még más paramétereket is (lásd: Paraméterek), de erre elég ritkán van szükség.
Paraméterek
HM_VESZ infile [opció] [opció] ...
Import leíró fájl
A program egy konfigurációs fájlból tudja, hogy milyen rekordot hogyan kell kezelnie. Abban van leírva, hogy mely rekordokat kell eldobnia, újként felvennie, módosítani. Az egyes rekordok kezelésének módja is itt van megadva (mely mezővel mit kell csinálni). Az import leíró szövegállomány szerkezete azonos, tartalma pedig lehet azonos a TextLib adatbázisok közötti importot végrehajtó TL_VESZ.EXE program import leíró állományával. Ezt a fájlt először az aktuális könyvtárban keresi a program, ha itt nem találja, akkor megnézi ott is, ahol a HM_VESZ.EXE van. Az Import leíró fájl részletes leírása.
Input fájl
A program inputja HunMarc formátumú. Ez egy szövegfájl, szerkezetét az Országos Széchenyi Könyvtár által Budapesten 1994-ben kiadott "HunMarc: a bibliográfiai rekordok adatcsere formátuma" című kiadvány írja le. A szabvány nem köti meg a HunMarc állományban alkalmazható karakterkészletet, a HM_VESZ.EXE program egyelőre négyféle készlet fogadására készült fel:
Az import szövegállomány kódkészletének megadását az import leíró fájl felépítését itt ismerheti meg.
A használható elnevezések: MNBCD, OSZK1, OSZK2 és CWI. Ha nem adja meg, az alapértelmezés MNBCD lesz.
Az import szövegállomány karaktereit a program <HM_CHAR> szerint konvertálja a TextLibbe.
A HunMarc és TextLib rekordok közötti mező-mező megfeleltetést <HM_MEZO> írja le.
LOG fájl
Minden import alkalmával a program készít egy ún. LOG fájlt, amibe mindenféle információkat kiír. Pl:
História fájl
A program készít egy história fájlt is, amiben az összes import fontosabb adatai fel vannak sorolva (Mikor mennyit importáltunk). A História fájl felépítése magától értetődő, HM_VESZ.HST néven az adatbázis könyvtárában találjuk.
Rekordba írt rendszer megjegyzések
Az import során a program több rekord rendszer megjegyzés mezőjébe is ír szövegeket, minden esetben #HM kezdetűt. Magyarázatukat <hm_megj> tartalmazza. Egy import után a LOG fájl megnézése után ezeket a rekordokat érdemes lekeresni, és megnézni.
Hibakódok
A program futása után beállítja a DOS-ban az ERRORLEVEL változót. Ebből tudhatjuk, hogy milyen hibával ért véget a program.
0 - minden rendben volt ?? - hibakód
Működés
A program beolvassa az input fájlban található rekordokat. Azokat, amikkel nem kell semmit csinálnia (az import leíró fájlból tudja) eldobja. A többit pedig a megadott utasítások szerint feldolgozza. Menet közben számolja, hogy hány új rekordot vett fel, hányat módosított, és hányat hagyott érintetlenül.
A problémás rekordokat kétféle módon kezeli:
A DBSTRUCT program segítségével tudhatjuk meg, hogy az adatbázisban milyen adatfájlok, rekordtípusok és mezők vannak.
Hunmarc export - MOKKA-ba küldéshez
Célja
A MOKKABA.BAT segítségével egy találati halmazt (egy dolgozó elmentett halmazát) exportálhatjuk HunMarc formátumban, hogy az a MOKKA-ba küldéshez a lehető legjobb legyen.
Használata
Használata megegyezik a HM_KULD programéval, mivel ez a batch is azt a programot hívja. A különbség csak a default konfigurációs fájl (mokkaba.cfg) és a default log fájl (mokkaba.log).
Hunmarc export - MOKKA-ból érkezett rekordokra
Célja
A MOKKABOL.BAT segítségével egy HunMarc formátumú fájlban levő rekordokat tudunk a TextLib adatbázisunkba importálni.
Használata
Használata megegyezik a HM_VESZ programéval, mivel ez a batch is azt a programot hívja. A különbség csak a default konfigurációs fájl (mokkabol.cfg) és a default log fájl (mokkabol.log).
HunMarc rekordok
Fontos, hogy ha MOKKA-ból töltönk le rekordokat (pl. a WEB-es felületről), akkor azokat HunMarc bináris formátumban, lehetőleg ALA/ANSEL karakterkészletben töltsük le. A mokkabol.cfg ennek megfelelően van beállítva.
A TL_VESZ.CFG és a HM_VESZ.CFG olyan fegyver, amellyel az import lefolyását szinte tetszőlegesen befolyásolhatjuk, a beállítások végtelen lehetősége pedig garantálja, hogy a betöltendő rekordok és a fogadó adatbázis egy hibátlan egységet alkothasson. Egy tényező mégis gátat szabhat törekvésünknek, az pedig a csereállomány, az importálandó rekordok állományának minősége.
Amennyiben a betöltendő szöveg hiányos vagy hibás, akkor az gyakran már az import végén kiderül, és elkerülhetetlenül nyoma marad az adatbázisban is. A betöltés befejeződésekor gyakran léthatunk az alábbi szöveghez hasonlót a képernyőn vagy a .LOG szöveg végén:
!! Fel nem oldott hivatkozás:113 !! (Rendszer megj. alapján kereshető)
A figyelmeztetés oka, hogy a program 113 esetben kapcsolatot épített volna ki két rekord között, de a párok egyik tagját nem találta meg a betöltött zövegben. Tehát pl. egy többkötetes könyvnek vagy a közös adata vagy valamelyik kötete hiányzik, pedig a hivatkozás szerint léteznie kell. A hiányzó rekordokat az import üresen létrehozza, és a rendszer megjegyzés mezőbe beírja a hibát:
#HM:üres maradt #!üres maradt
Az első a HunMarc, a második a TextLib rekordok hibájának következménye. A jelenség megszüntetéséhez az exportba kell beleavatkozni, amit a HunMarc állományoknál általában nem tudunk megtenni. Tegyünk egy kis kitérőt a probléma részleteinek áttekintésére!
Kiindulópont a rekordok kapcsolata. A TextLib adatbázisban rengeteg féle rekord tud egymással kapcsolatba kerülni, mindazok, amelyek bevitelekor a mezőbe beszúrással kell folytatni a munkát: közös és kötet, kötet és példány, kötet és szerző, kötet és sorozat, testület és névváltozata, olvasó és kategóriája, szóval akár százával sorolhatnánk. A HunMarcban ez a dolog sokkal egyszerűbb, csak közös és kötet, kötet és analitika valamint közös és/vagy kötet és sorozat kapcsolat létezik. A kapcsolatok lehetséges számától függetlenül akkor működhet jól az import program, ha az összekapcsolandó rekordok mindegyike megvan vagy a csereállományban vagy a fogadó adatbázisban. A feltétel teljesülését az export garantálhatja, ha minden összekapcsolni kívánt rekordot elhelyez a csreállományban. Látható tehát, hogy a TextLib export-import műveletében a kulcs a mi kezünkben van.
Más a helyzet a HunMarc rekordokkal, a csereállományt készen kapjuk (vesszük), megváltoztathatatlan tartalommal. Ezekben a fájlokban háromféle olyan hiba szokott előfordulni, ami a kapcsolatok felépülésének elmaradásához vezet:
787 0 $w 796630
001 000000796630
Az import végeredményét a vezérló állomány tartalmának módosításával szélsőséges határok között változtathatjuk. A betöltendő állomány és a fogadó adatbázis tartalmának ismeretében sem mindig egyszerű feladat olyan .CFG-t készíteni, amelyik éppen az elvárt végeredményhez vezet. Közismert hiba a rekordok indokolatlan többszöröződése vagy eltűnése, és az összetartozó rekordok elszakadása vagy a nem összetartozók összekapcsolódása.
Rengeteg rossz .CFG van forgalomban, és azok közül több is az InfoKertől származik. Ezek speciális célokra jók lehetnek, de sok helyzetben biztosan adatbázis hibákat okoznak. Két szabályt feltétlenül be kell tartani az importáláskor:
Induljunk tiszta lappal, készítsünk egy TL_VESZ.CFG állományt az elejétől kezdve! Szükségünk van egy egyszerű szövegszerkesztőre, mint amilyen pl. az EDIT a DOS-ban, a Jegyzettömb vagy a WordPad a Windowsban. Sok formai szabályt be kell tartanunk, az érdemi részek rögzített készletből választható kulcsszavak, amelyekben egyetlen "helyesírási" hiba sem lehet. Ha az import program nem képes értelmezni a szövegünket, akkor kiírja az elsőként talált hibás sor számát, és leáll.
A .CFG állományban elhelyezhetünk saját magunk számára megjegyzéseket, az erre a célra szánt sorokat kezdjük # karakterrel. A legelső nem megjegyzés sor tartalma kötelező:
TextLib Import leiro file - InfoKer 1995
Kodkeszlet:CWI Kodkeszlet:MNBCD Kodkeszlet:OSZK1
A betöltés célja Az importot vezérlő szövegben (általában TL_VESZ.CFG vagy HM_VESZ.CFG) háromféleképpen rendelkezhetünk a betöltés céljáról:
Cel:T Cel:B Cel:M
| . | Törlés | Bevitel | Módosítás |
|---|---|---|---|
| A művelet, ha azonosak | törlés | -semmi- | módosítás |
| A művelet, ha különbözők | -semmi- | bevitel | bevitel |
A speciális jelek sorsa Ezek a speciális jelek valóban nagyon speciálisak, kizárólag HunMarc állományokban fordulnak elő. Azokban a könyvtári rendszerekben, amelyek a TextLibbel ellentétben képtelenek szabványos katalóguscédula nyomtatására, a program hiányosságát gyakran a nyomtatáshoz szükséges jelek mezőbe rögzítésével szüntetik meg. Így kerül a szabályosan leírt adat mögé a " /", a " :", a " ;", stb. Ezeket - mivel teljesen fölöslegesek - az import program levágja, ha akarjuk. Erre szolgál a
Teljesmezo:I Teljesmezo:N
bejegyzések egyike a .CFG következő sorában. "I" jelenti, hogy szükségünk van a teljes, csonkítatlan mezőre, meg kívánjuk tartani a speciális jeleket is, "N" pedig azt, hogy nem. Nem követünk el hibát, ha a
Teljesmezo:N
sort mindig beírjuk a .CFG-be, TextLib importnál fölösleges, de nem zavar, HunMarc betöltésnél pedig vág, ha van mit.
Eddig négy érdemi sora van a tervezett .CFG-nek, valahogy így:
TextLib Import leiro file - InfoKer 1995 Kodkeszlet:CWI Cel:M Teljesmezo:N
!! 1.HIBA (313): Rossz leíró fájl / c:\textlib\exe\tl_vesz.cfg (1. sor) !! !! 1.HIBA (318): Rossz 'Kodkeszlet:' sor / CVI (2. sor) !! !! 1.HIBA (319): Rossz 'Cel:' sor / N (3. sor) !! !! 1.HIBA (344): rossz 'Teljesmezo:' sor / M (4. sor) !! !! 1.HIBA (314): Rossz sor / Tejesmezo:N (7. sor) !!
A betöltendő adatfájlok és rekordtípusok
A TextLibbel dolgozók sok hasonlóságot találnak az eltérő célokra szolgáló űrlapok között. Rokonai egymásnak a különböző dokumentumtípusok beviteli formátumai a képernyőn, és még az eltérő bibliográfiai szinthez tartozók is gyakran hasonlítanak egymásra. A könyv kötet beviteli ablak rengeteg mezője visszaköszön egy másik dokumentumtípusnál, pl. a térkép részegységnél és annak egy másik bibliográfiai szintjénél, a térképek közös adatánál is. A hasonlóság oka az, hogy ezek az űrlapok bár sokfélék, de egyetlen közös logikai szerkezeten alapulnak, amit a TextLib rekordtípusnak nevez. Ugyanabba a rekordtípusba tartoznak tehát az azonos adategyüttessel leírható rekordok, mint pl. a sokféle dokumentumtípusé, a különböző osztályozásoké vagy tárgyszavaké, stb. (Természetesen nem kötelező minden űrlapon szerepelni a rekordtípus összes mezőjének. Pl. a kötetnek van közös adata és példánya, ellenben a közösnek nincs. Van viszont kötete, ami a kötetnek nincs, és sorolhatjuk százával a példákat.)
Ha tudjuk, hogy egy kitöltött űrlap tartalmából a TextLib adatbázisában rekord lesz, akkor érthetővé válik egy újabb fogalom, az adatfájl. Ez nem más, mint a rekordok tárolási helye. Az eltérő tárolási hely alapján tud a program különbséget tenni az azonos rekordtípushoz tartozó, tehát egymáshoz nagyon hasonló felépítésű adategyüttesek között. Az eddigiekből nem következik, de természetesen igaz, hogy nem kötelező több adatfájl rekordjainak logikai felépítését összevonnni egy rekordtípusba. Pl. az ALKOTO rekordtípusba kizárólag az azonos nevű, tehát szintén ALKOTO adatfájl rekordjai tartoznak.
Az adatcsere programok ismerik a két fogalmat, így nekünk is ismernünk kell, ha e fontos képességet ki akarjuk használni. Az export és import műveletében a program válogatni tud kiküldéskor és betöltéskor is a rekordok között. Ehhez jó kiindulópont a rekordtípus vagy az adatfájl. Szabadon dönthetünk, hogy mivel foglalkozzon és mivel ne az adatcsere. Elhatározásunkat a .CFG-ben írjuk le a következőhöz hasonló módon:
&r DOKUMENTUM &d DOK &d KOTET &d AUDIOKOTET
Az első sor szerint minden olyan adategyüttessel van tennivalója az adatcserének, amelyik a dokumentum rekordtípusba tartozik. Márpedig ebből elég sok van:
Amennyiben a közös kezelés nem felel meg - és hogy miben, arról az összehasonlítás szempontjainál lesz szó - akkor minden egyes adatfájl rekordjairól külön rendelkezhetünk, ahogy ezt a példa 2-4. sora mutatja. A program ésszerűen kezeli a kivételeket: ha adatfájlra érvényes leírást készítünk, akkor a program a szerint jár el. Így a példában a DOK (könyv közös adat), KOTET (könyv kötet) és az AUDIOKOTET (audiovizuális kötet) adatfájl rekordjait másképp kezelheti, mint az egyéb DOKUMENTUM rekordtípusba tartozó rekordokat. Amennyiben pedig az első sort elhagyjuk, akkor az összes DOKUMENTUM rekordtípusba tartozó adategyüttes közül csak a DOK, a KOTET és az AUDIOKOTET rekordokat veszi tekintetbe az adatcsere.
Fontos tudni, hogy TextLib rekordok importjához a rekordokba beépült, almezőnek nevezett szerkezeti elemek leírását is el kell készíteni. A legfontosabb ilyenek az alábbiak:
&r CIMADAT &r PARHCADAT &r ETO_ALM &r KOZREMUKODO &r KIADAS &r NYOMTATAS &r SOROZATLEIRAS &r MELLEKLET
&r PELDANY &d PELDANY &d AUDIOPELDANY &d IDOPELDANY
Az összehasonlítás szempontjai Ahogy az import program egymás után dolgozza fel a rekordokat, mindegyikről döntést kell hoznia, mi történjen vele. Korábban részletezett két tényező, az import célja és az adatfájlról és/vagy rekordtípusról leírt rendelkezés alapjában befolyásolja a történést. Most azonban újabb szemponthoz érkeztünk.
A fogadó adatbázis tartalmának is meghatározó a szerepe. Az importtól a célként
megjelölt viselkedést várjuk el, a kijelölt rekordokat törölje vagy módosítsa,
és csak akkor vigyen be újként valamit, ha az még nincs meg a mi
adatbázisunkban. A helyes viselkedéshez a fogadó adatbázisban keresni kell az
érkezővel azonos reköordo(ka)t, és a találat ténye továbbá az import célja
együtt határozza meg a további tennivalókat. A kereséshez pedig előre
kiválasztott mezőket használ a program, és azok tartalmának összehasonlítása
után dönt az egyezőségről.
Az összehasonlítás szempontjainak meghatározásánál tehát a cél az
egyértelműség: mutatkozzon két rekord azonosnak, ha valóban az, és lássék
különbözőnek, ami különbözik. Nem akarhatjuk, hogy újkent bekerüljön az
adatbázisunkba az, ami már ott is megvan, es persze azt sem, hogy az érkező
rekord átírjon egy meglevőt, holott semmi közük egymáshoz. Mint kiderül majd,
ez egy csöppet sem egyszerű feladat. Követhetünk el hibát mindkét irányban, és
készítünk is .CFG-t, ami ezt bemutatja.
A vezérlő állományban aprólékosan szabályozhatjuk, hogy mit vizsgáljon az
import program, amikor két rekordot összehasonlít. Szinte tetszőleges mezőket
jelölhetünk ki, azoknak a tartalmát veti egybe a program páronként az érkező és
már meglévő rekordokban. Az erre vonatkozó utasítást az "Azonosito" szóval kell
kötelezően kezdeni, és ahogy a következő példa is mutatja, mindig az adatfájl
és/vagy a rekordtípus megjelölésével együtt érvényes.
&r PELDANY Azonosito:VONALKOD
&r FOLDRAJZ Azonosito:MEGNEVEZES
- Az érkező új a meglévők bármelyikével azonos - az összehasonlított tartalomban valóban az -, válasszunk ki közülük egyet, bármelyiket. - Az érkező új a meglévők egyikével sem azonos, mert valószínüleg a látszat ellenére a régi három sem az. Hiszen ha azonosak lennének, akkor nem kellene belőlük három.
A két rossz választás közül a program a második mellett dönt, mert megvan az esélye annak, hogy a rekordok valóban különböznek, csak az összehasonlítás rossz. Ha belegondolunk, ez így is van. Javításként egészítsük ki az azonosító mezők sorát!
&r FOLDRAJZ Azonosito:MEGNEVEZES TIPUS
&r DOKUMENTUM Azonosito:DOK / RESZJELZES MEGJEVE FOCIM PARHCADAT CIMADAT ALCIM SZERZO Azonosito:FOCIM CIMADAT PARHCADAT / SZERZO MEGJEVE DOK RESZJELZES ALCIM
!! 1.HIBA (320): Rossz mező / REZSJELZES (11. sor) !! !! 1.HIBA (330): Túl sok azonosító mező (max 8) / (9. sor) !! !! 1.HIBA (331): Túl sok 'Azonosito:' sor (max 4) / (14. sor) !! !! 1.HIBA (332): Nem adott meg indexelt mezőt / (11. sor) !! !! 1.HIBA (334): Másodszori definíció / (20. sor) !!
&r DOKUMENTUM Azonosito: ISBN Azonosito: ISSN
&r DOKUMENTUM Azonosito:ISBN FOCIM
&r DOKUMENTUM Azonosito:ISBN / FOCIM
&r DOKUMENTUM Azonosito:ISBN Azonosito:ISSN Azonosito:DOK / RESZJELZES MEGJEVE FOCIM PARHCADAT CIMADAT ALCIM SZERZO Azonosito:FOCIM CIMADAT PARHCADAT / SZERZO MEGJEVE DOK RESZJELZES ALCIM
&r DOKUMENTUM Azonosito:...
&d AUDIODOK Azonosito:... &d AUDIOKOTET Azonosito:... &d AUDIOANAL Azonosito:...
Mivel csak az audiovizuális dokumentumok importjához talál leírást a program a .CFG-ben, minden mást kihagy, valóban szűrőként viselkedik tehát ez a pár sor.
Egy másik lehetséges oka az adatfájlonkénti leírásnak az egyszerűsítés lehetne. Talán könnyebb áttekinthető szabályokat alkotni, ha nem akarunk annyi mindent egy csapásra megoldani. Az audiovizuális közös adatokra (AUDIODOK) a dokumentumoknál megismert egyik sor kis átalakítással elegendőnek látszik. Nyugodtan kihagyhatjuk a DOK Közös adatai és a RESZJELZES Kötetjelzés mezőt, mert ilyenek a közös rekordban nincsenek. Helyettük vonjuk be a KOZREMUKODO Közreműködők mezőt:
&d AUDIODOK Azonosito:FOCIM CIMADAT PARHCADAT / SZERZO KOZREMUKODO MEGJEVE ALCIM
&d AUDIOKOTET Azonosito:DOK / RESZJELZES MEGJEVE FOCIM PARHCADAT CIMADAT ALCIM SZERZO
Jó ez a többkötetesek köteteihez, de nem jó a magányos kötetekhez. Kellene legalább még egy sor, és akkor ugyanott vagyunk, mint a rekordtípus egészét szabályozó leírás készítésekor voltunk. Leszögezhetjük tehát, hogy adatfájlonként elkülönülő szabályrendszert kizárólag szűrés céljára indokolt felállítani.
Foglaljuk össze az érkező és bent levő rekordok összehasonlításának lényegét!
A vizsgálat legelső mozzanata, hogy a betöltő program az érkező rekord importazonosítója alapján keres. A .CFG szabályrendszere akkor lép működésbe, ha ez a keresés eredménytelen marad.
A .CFG-ben négy sorban adhatunk meg azonosító mezőket, mindegyikben nyolcat. A program egymás után dolgozza fel a sorokat, amíg meg nem állapítja a rekordok azonosságát. Új lesz az érkező rekord, ha egyik sor alapján sem állapítható meg egyezés, vagy ha több azonos is van a fogadó adatbázisban. Az azonosság feltétele a felsorolt mezők mindegyikének páronként egyező tartalma. Igaz az egyezés, ha a mezők azonos tartalommal kitöltöttek vagy ha üresek. Az összehasonlításba bevonni kívánt rekordok keresésénél az üres mezők természetesen figyelmen kívül maradnak. Az azonosító mezők felsorolását a "/" jellel kettéválaszthatjuk. A program csak a jel előtti mezőket használja kereséshez, így a keresést felgyorsíthatjuk és/vagy egyértelműsíthetjük.
Még egyszerűbben: két rekord azonos, ha egyetlen rekord két adatbázisban előforduló két változata, vagy ha az összehasonlításra kijelölt mezőinek a tartalma azonos.
Az összehasonlítás szempontjainak kidolgozásában az elvi megfontolások mellett gyakorlati segítséget is kaphatunk. Jó lenne meggyőződni az azonosítás megbízhatóságáról, miközben a rekordok ezrei ömlenek be a fogadó adatbázisba, de erre sajnos nincs mód. A betöltés befejeztével azonban az egyesített adatbázis tartalmán kívül a folyamat mozzanatait leíró TL_VESZ.LOG vagy HM_VESZ.LOG nevű szövegállomány is fontos információkkal szolgál. (Lásd a 7. hírlevélben !) Ennek a szövegállománynak a tartalmát a .CFG-be írt kiegészítéssel kibővíthetjük az összehasonlítás pontosságának könnyebb megítélése céljából. A vezérlő utasítás alakja a következő:
&r DOKUMENTUM Azonosito:... Hasonlo:...
&r DOKUMENTUM Azonosito:ISBN Azonosito:ISSN Azonosito:DOK / RESZJELZES MEGJEVE FOCIM PARHCADAT CIMADAT ALCIM SZERZO Azonosito:FOCIM CIMADAT PARHCADAT / SZERZO MEGJEVE DOK RESZJELZES ALCIM Hasonlo:ISBN Hasonlo:FOCIM CIMADAT PARHCADAT SZERZO
Az adatbázisba kerülés módja Túljutva az összehasonlítás bonyodalmain a program tennivalója két ágra bomlik:
Bent levő Érkező
FOCIM: A magyar nemzet megszületése FOCIM: A magyar nemzet megszületése
SZERZ_KOZL: Kristó Gyula SZERZ_KOZL: Kristó Gyula
KIADAS: KIADAS:
1.XMEGJ_HELYEK: Budapest 1.XMEGJ_HELYEK: Budapest
KIADOK: Kossuth KIADOK: Kossuth
NYOMTATAS:
1.XMEGJ_HELYEK: Budapest
KIADOK: Kossuth
2.XMEGJ_HELYEK: Szekszárd
KIADOK: Szekszárdi Ny.
MEGJEVE: 1998 MEGJEVE: 1998
OLDALSZAM: 210, [3] p. OLDALSZAM: 210, [3] p.
MERET: 20 cm MERET: 20 cm
ISBN: 963-09-3990-8 ISBN: 963-09-3990-8
KOTES: fűzött KOTES: fűzött
AR_TERJFELT: 990,- Ft AR_TERJFELT: 990,- Ft
BIBL_MEGJEGYZES: Bibliogr.: p. 207-
[211]. és a lábjegyzetekben
SZERZO: SZERZO: Kristó Gyula
1.NEV: Kristó Gyula
EVEK: 1939
NYELV: magyar NYELV: magyar
ETO_ALM: ETO_ALM:
1.ETOSTRING: 943.9"08/12" 1.ETOSTRING: 943.9".../12"
FO: Magyarország története
TARGYIDO: "08/12"
2.ETOSTRING: 316.356.4(=945.11) 2.ETOSTRING: 316.356.4(=945.11)
FO: nemzet / szociológia
ETNIKAI: magyarok
SZAKJELZET: 943.9
CUTTER: K 95
PELDANY:
1.VONALKOD: 001000062185N
2.VONALKOD: 001000051089O
ETO2_ALM:
1.ETOSTRING: 9(439)"08/12"
FO: történelem
FOLDRAJZ: Magyarország
TARGYIDO: 0800/1299
2.ETOSTRING: 307(439)"08/12"
FO: társadalmi tudat
FOLDRAJZ: Magyarország
TARGYIDO: 0800/1299
3.ETOSTRING: 309(439)"08/12"
FO: társadalomtörténet
FOLDRAJZ: Magyarország
TARGYIDO: 0800/1299
A mezők kijelölése Az előbb felsorolt parancsok önmagukban használhatatlanok, csak a rekord egy vagy több mezőjének megnevezésével együtt érvényesek. Vagyis szinte tetszőleges részletességgel megadhatjuk, hogy az érkező rekord mezőit átvenni kell-e illetve eldobni, vagy a meglevőket kitölteni, módosítani illetve vegyíteni az újakkal. Ezek után a dokumentum rekordtípus importját vezérlő leírás immár teljessé válik:
&r DOKUMENTUM Azonosito:ISBN Azonosito:ISSN Azonosito:DOK / RESZJELZES MEGJEVE FOCIM PARHCADAT CIMADAT ALCIM SZERZO Azonosito:FOCIM CIMADAT PARHCADAT / SZERZO MEGJEVE DOK RESZJELZES ALCIM Kitolt:/MIND /RENDSZER Vegyit:ETO_ALM Eldob:KIVONAT
&r DOKUMENTUM Azonosito:ISBN Azonosito:ISSN Azonosito:DOK / RESZJELZES MEGJEVE FOCIM PARHCADAT CIMADAT ALCIM SZERZO Azonosito:FOCIM CIMADAT PARHCADAT / SZERZO MEGJEVE DOK RESZJELZES ALCIM Kitolt:/MIND /RENDSZER Vegyit:ETO_ALM Eldob:PELDANY &r PELDANY Azonosito:VONALKOD Kitolt:/MIND /RENDSZER
# # Dokumentumok es kapcsolataik betoltesehez # TextLib Import leiro file - InfoKer 1995 Kodkeszlet:CWI Cel:M Teljezmezo:N &r DOKUMENTUM Azonosito:ISBN Azonosito:ISSN Azonosito:DOK / RESZJELZES MEGJEVE FOCIM PARHCADAT CIMADAT ALCIM SZERZO Azonosito:FOCIM CIMADAT PARHCADAT / SZERZO MEGJEVE DOK RESZJELZES ALCIM Kitolt:/MIND /RENDSZER Vegyit:BIBL_MEGJEGYZES PELDANY &r PELDANY Azonosito:VONALKOD Kitolt:/MIND /RENDSZER &r IDOSZAM Azonosito:KOTETE / SZAMOZAS KELTEZES MEGJEVE EVFOLYAM Kitolt:/MIND /RENDSZER &r CIMADAT Kitolt:/MIND /RENDSZER &r PARHCADAT Kitolt:/MIND /RENDSZER &r ALKOTO Azonosito:NEV NEVKIEG EVEK Hasonlo:NEV Kitolt:/MIND /RENDSZER &r TESTULET Azonosito:NEV IDOSZAK SORSZAM SZEKHELY Hasonlo:NEV Kitolt:/MIND /RENDSZER &r ETO_ALM Kitolt:/MIND /RENDSZER &r ETO2_ALM Kitolt:/MIND /RENDSZER &r SPEC_OSZT Azonosito:KOD Kitolt:/MIND /RENDSZER &r TEZAURUSZ Azonosito: KULCS Hasonlo: KULCS Kitolt:/MIND /RENDSZER &r FOLDRAJZ Azonosito:MEGNEVEZES TIPUS Kitolt:/MIND /RENDSZER &r KOZREMUKODO Kitolt:/MIND /RENDSZER &r KIADAS Kitolt:/MIND /RENDSZER &r SOROZATLEIRAS Kitolt:/MIND /RENDSZER &r SOROZAT Azonosito:FOCIM PARHCADAT ISSN Kitolt:/MIND /RENDSZER &r MELLEKLET Kitolt:/MIND /RENDSZER &r MU Azonosito:EGYSCIM SZERZO KELETKEZESIIDO Kitolt:/MIND /RENDSZER &r PARH_SZAMOZAS Kitolt:/MIND /RENDSZER
HunMarc fájlok olvasható formában történő kiírásához használható.
Használata
Használat: HUNDIR in [/n] [/n-m] [/oout]
A rekordokat a következő formában jeleníti meg:
mezőazonosító
almezőazonosító érték
almezőazonosító érték
...
...
Ilyenekkel fogunk tehát találkozni:
020 $a 963-375-130-6 $j fîuzčott 080 0 $a 894.511-312.5 100 10 $a Nemere $j Istvâan $d 1944- 245 12 $a Lazarus doktornîo $c Melissa Moretti 260 $a [Budapest] $b Anno, $c 2000 300 $a 245 p. $c 20 cm
Az mnb5123.iso fájl első 20 rekordjának kiiratása a képernyőre:
HUNDIR /1-20 mnb5123.iso
HUNDIR mnb5123.iso /omnb5123.lst
Célja
A TextLib adatbázis szerkezetének megtekintése. Megnézhetjük milyen adatfájlok, rekord típusok, indexfájlok, stb vannak az adatbázisban. Az egyes rekord típusokhoz tartozó mezőkről és azok indexelési módjáról is felvilágosítást kaphatnuk.
Érdemes egyszer kinyomtatni az adatbázis szerkezetét, hogy mindig kéznél legyen. Valószínűleg a rendszergazdán kívül senkinek sem lesz rá szüksége.
Az adatbázis szerkezet leírásánál használt fogalmak és jelek:
Dataset: a TextLib adatállományai a lemezen, egy-egy set több adatfájlt foglalhat magába
A leírásban a datasetek sorszáma és neve szerepel.
Rekordtípus: DOKUMENTUM DOKUMENTUM
Adatfájl: KOTET DOK
-?????????????????Ş -???????????????????Ş
-Rekord1 - -Rekord2 -
+?????????????????+ +???????????????????+
- - - -
-89 DOKUMENTUM_DOK-<-->-87 DOKUMENTUM_KOTET-
- - - -
- - - -
- - - -
L?????????????????- L???????????????????-
Indexfájlok egyenként: A leírásban az indexfájl sorszáma, az azonosítója, a neve, a befoglaló indexset neve (Iset), az indexkulcs típusa (Kulcstip), a rekordhivatkozás típusa (Dreftip), az indexelési mód (IdxMód), az összehasonlító tábla sorszáma (Tbl), az indexfájl jellemzői (Status), és a belekerülő mezők felsorolása szerepel. Pl: 74.indexfájl: SZERZOJE Szerzője Iset:TL_BIBL Kulcstip:str Dreftip:dref IdxMód:teljes Tbl:8 Status: (0006) Postingos Kapcsolódó MU_SZERZO(51_48), indirekt DOKUMENTUM_SZERZO(53_70), indirekt
A TextLib programban (egyelőre) vannak olyan helyek, ahol a rendszergazdának adatfájl vagy rekordtípus-sorszámot kell megadnia. Ilyen például a felhasználói jogok definiálása.
Használata
Egyszerűen indítsuk el a programot a megfelelő paraméterrel. Ha nem tudjuk, hogy mik a paraméterek, akkor a /? opcióval kiírja őket a program.
A program a képernyőre ír, ha fájlba akarjuk menteni az eredményt, akkor irányítsuk át az output-ot a DOS lehetőségeit használva: .BAT DBSTRUCT paraméter > outfile
Paraméterek
DBSTRUCT [param]
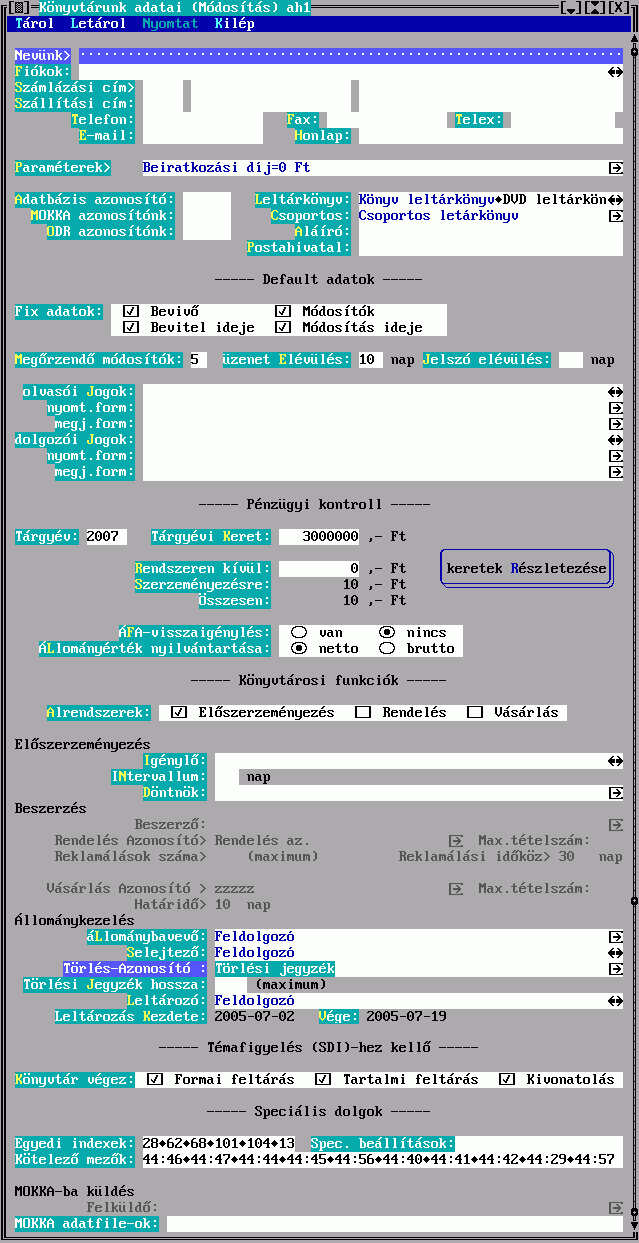
A könyvtár adatait csak a rendszergazda módosíthatja, az ő menüjében a Rendszer / Könyvtárunk adatai menüpontból kiindulva. A következő ablakot láthatja:
A fontosabb (vagy nem magától értetődő) mező ismertetése:
Nevünk: A könyvtár neve. Ez jelenik meg a munkaállomásokon, ez kerül a kimenő levelek fejlécébe, stb. Kitöltése kötelező.
Számlázási cím: Megrendelő levelek nyomtatásakor ezt a címet írja a program a levélbe. Kitöltése kötelező.
Szállítási cím: Csak akkor kell megadni, ha különbözik a Számlázási cím-től.
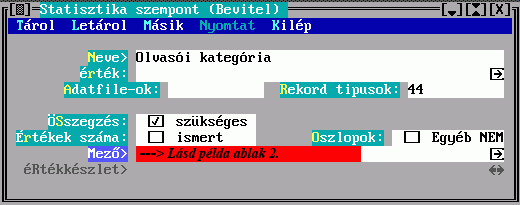
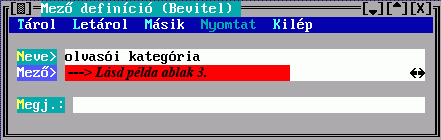
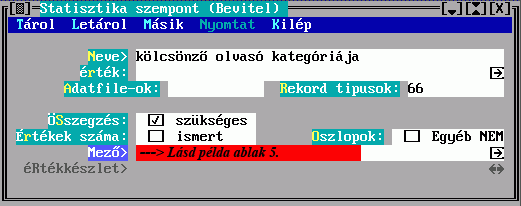
Paraméterek: A könyvtár által kezelt dokumentumokhoz való hozzáférés körülményeit az "átlag"-olvasó vonatkozásában szabályozó adatokat jelenti; elkülönült adatcsoportként való szerepeltetését az indokolja, hogy nemcsak a könyvtár egészére, hanem megfelelő szempontok szerint osztályozott részeire (állományok, dokumentum-osztályok) ill. a felhasználók megfelelő csoportjaira, az ún. olvasói kategóriákra, sőt ezek kombinációjára is megadhatók ilyen paraméterek (lásd PARAMS.txt).
Adatbázis azonosító: Kitöltése csak akkor szükséges, ha exportálni akarunk az adatbázisból. Ilyenkor egy mindenki másétól különböző azonosítót kell megadni. A GT tagoknak osztottak ki ilyen azonosítókat, az FSZEK adatbázisa pl. a 00100-as.
Leltárkönyv:
Csoportos leltárkönyv:
VKOD maszk: Azok a könyvtárak használhatják, akik megvették azt a TexTLib kiegészítést, ami a bejövő vonalkódok egy részét ki tudja hagyni. Más könyvtárakban ez a mező nem is látszik.
Rekord fix adatok tárolása: Itt lehet megadni, hogy a rekordok tárolásakor milyen plussz információk kerüljenek be a rekordba.
Megőrzendő módosítók: A rekord utolsó módosítóit is tárolja a TextLib. Maximum azonban annyit, amennyit itt megadtunk. Kezdeti értéke: 5
Üzenet Elévülés: Jelenleg még nem használt.
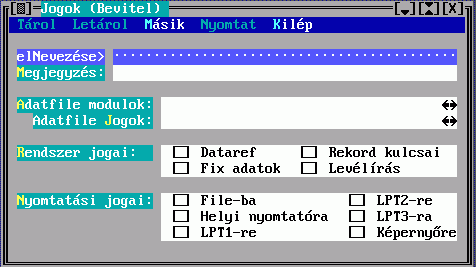
Olvasói Jogok: Jog rekordokat (jogok.txt) szúrhatunk be ide. Ezzel minden olvasónak tudunk jogot adni valamihez (pl: nyomtatás), nem kell egyenként minden olvasóhoz hozzárendelni.
Dolgozói Jogok: A minden dolgozót megillető jogokat itt adhatjuk meg.
Tárgyévi Keret:
Rendszeren kívül:
Felhasználás Szerzeményezésre:
Összesen:
ÁFA-visszaigénylés:
ÁLlományérték nyilvántartása:
Funkciók: Itt tudjuk bejelölni, hogy egyes alrendszerek közül a könyvtár melyeket szándékozik használni. Bármikor be lehet állítani egy alrendszer használatát, de kikapcsolni csak olyankor lehet, mikor nincs semmi függőben az adott alrendszeren belül (a program figyelmeztet, ha igen).
Igénylő:
Intervallum:
Döntnök:
Beszerző:
Vásárlás Azonosító: Az előszerzeményezés alrendszer használatakor meg lehet a vásárlási listák automatikusan generálandó azonosítóinak a formáját. Ha ezt nem adjuk meg, nem fogunk tudni vásárlási listát készíteni.
Rendelés Azonosító > Ha használjuk a rendelés alrendszert, akkor kötelező megadni a rendeléskor automatkusan generálódó azonosítók formáját.
Reklamálások száma> A rendelés alrendszer használatánál meg kell adni, hogy a könyvtár egy megrendelés esetén hányszor reklamál, mielőtt lemondja a megrendelést. Az egyes szállítóknál ettől eltérő érték is beállítható.
Reklamálási időközök> A rendelés alrendszer használatánál meg kell adni, hogy a könyvtár milyen időközönként reklamál, ha a megrendelésre nem kap visszajelzést. Az egyes szállítóknál ettől eltérő érték is beállítható.
ÁLlománybavevő:
Egyedi indexek: Az itt megadott sorszámú indexfájlokba történő bevitel előtt a program egyediséget ellenőriz. Ha az indexfájl valóban egyedi, akkor a rekordot nem is lehet tárolni.
Pl: szóljon a program, ha olyan leltári számot adunk meg, ami már létezik (ha ezek általában egyediek). Vagy pl. alkotó bevitelnél szóljon, hogy van már ilyen nevű alkotó.
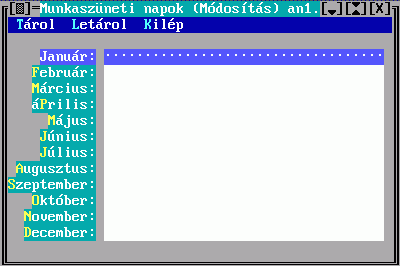
az alábbi alakú képernyőn adhatók meg a munkaszüneti napok:
Minden hónaphoz megadható, hogy mely napokon nincs nyitva a könyvtár. A program ezt több helyen automatikusan kezeli. Kölcsönzéskor például úgy határozza meg a határidőt, hogy ne essen olyan napra, amikor a könyvtár nincs is nyitva. A napok közé a szokásos ismétlés jelet kell bevinni, például az ALT-; billentyűkombinációval.
A program mindig azt tételezi fel, hogy az aktuális hónap utáni hónapokra az ezévi, a korábbi hónapokra pedig a jövő évi adatok vannak megadva. Például 1995. júnisban a július-december hónapot 1995. évinek, de a január-május hónapot már 1996. évinek gondolja. Mivel nem valószínű, hogy 1-2 hónapnál nagyobb intervallumokat kell kezelni, ezért elég negyed- vagy félévente aktualizálni az adatokat (ami a rendszergazda dolga).
Lásd: Olvasószolgálati dokumentáció
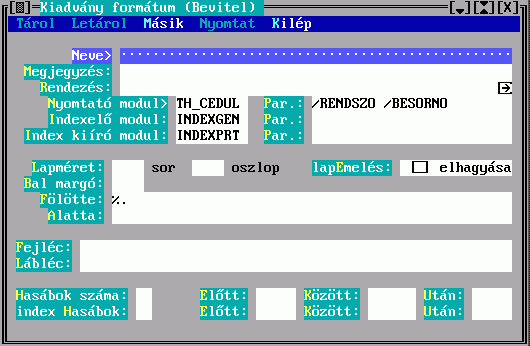
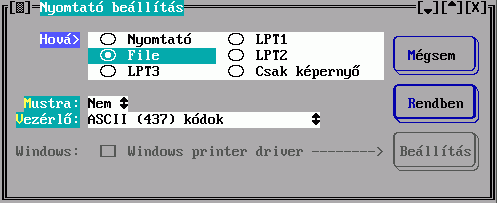
Ha nyomtatni akarunk, két különböző dolgot kell definiálnunk: az egyik a nyomtató típusának, bekötésének (soros port, novell nyomtató,...) megadása (bővebben: nybeall.txt), a másik pedig a nyomtatási formátumnak a megadása.
A TextLibben a nyomtatási formátum ugyanolyan rekord, mint az összes többi. Ilyen rekordoknak a beviteléhez és módosításához általában csak a rendszergazdának van joga.
A nyomtatási formátum megadása két fő részből áll. Egyrészt meg kell adnunk a nyomtatni kívánt lapok adatait (méret, hasábok száma, rekordok előtt, között, után nyomtatandó szövegek, stb), valamint meg kell adni azt a nyomtató modult (InfoKer által készített modulok, pl: TH_CEDUL, TH_LPRN, vagy az output nyelven megírt, és lefordított modulok), ami a nyomtatást végzi. Ez a modul határozza meg, hogyan jelennek meg az adatok (milyen mezőket kell kiírni egy rekordból, és azokat hogyan).
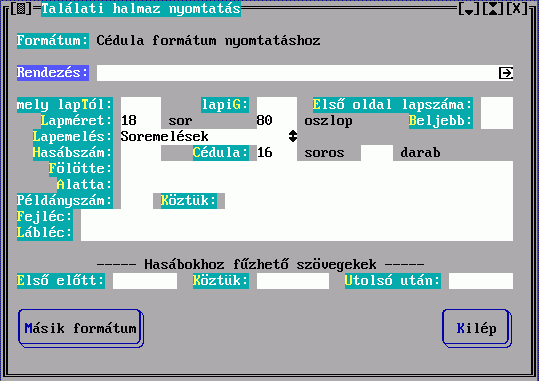
Lapok adatainak beállítása
A Lapméret mezőben adhatjuk meg, hogy a nyomtatón hány sor és hány oszlop kerüljön egy lapra. Ha üresen hagyjuk, akkor 65x78-as lapok készülnek. A Beljebb mezőben megadható, hogy hány karakter pozícióval kell minden sort beljebb kezdeni. A Hasábszám mező azt adja meg, hogy hány hasábba akarunk nyomtatni. Ha nem adjuk meg, akkor 1 hasábos lesz az output. A Cédula mező annak a megadására szolgál, hogy cédula nyomtatás esetén hány soros cédulák készüljenek. Ha a mögötte található darab mezőt is kitöltjük, akkor minden cédulából annyi darab készül (közvetlenül egymás után).
A Fölötte és Alatta mezőbe beírt szövegek minden kinyomtatandó rekord fölött és alatt megjelennek. Ide írhatunk speciális jeleket:
A Példányszám mezőben azt lehet megadni, hogy a nyomtatandót hány példányban akarjuk kinyomtatni. A Köztük mezőben megadott szöveget szeretnénk az egyes példányok közé. Ez pl. akkor hasznos, ha az olvasónak kinyomtatjuk, hogy miket kölcsönzött, és két példányt akarunk nyomtatni, hogy az olvasónak és a könyvtárnak is legyen. (Ha a nyomtató tud több példányos nyomtatást, akkor persze az az egyszerűbb, de pl. a hőnyomtatók nem tudnak ilyet)
A Fejléc és Lábléc a minden lap tetejére és aljára nyomtatandó szöveg megadásának helye. A fejlécben az & karakter helyett a lapszám jelenik meg. SHIFT/ENTER itt is használható ha több soros szöveget akarunk bevinni.
Több hasábos nyomtatás esetén a hasábok elé, közé és után írandó szöveget adhatunk meg a hasábok Előtt, Között és Után mezőben.
Nyomtató modulok
Nyomtató modulokat az output nyelv segítségével lehet létrehozni. Meg kell írni a rekordok megjelenítését végző programot, majd le kell fordítani a megfelelő programmal, ami létrehozza a nyomtató modult.
Természetesen a leggyakrabban szükséges feladatokhoz vannak előre elkészített nyomtató modulok, amiket nyugodtan használhatunk. Ezek:
| TH_CEDUL - cédula formátumok |
|---|
| TH_LPRN - lista nyomtatáshoz (főleg példányokhoz) |
| TH_CPRN - minden mezőt kinyomtat |
| TH_SYS - rendszer adatrekordok nyomtatásához (levél,help,...). |
| TH_EGYEB - levelek, helpek, tezaurusz, eto. |
| TH_OLV - olvasói formátum |
| TH_SLST - rendezési kulcsok nyomtatása |
OLV_SZAM - olvasók összeszámlálása (statisztika)
Ez a modul egy olvasó rekordokat tartalmazó találati halmaz kinyomtatására szolgál. Kétféle összesítést végez: állományonként és olvasói kategóriánként összeszámolja az érvényes és a lejárt olvasójeggyel rendelkező olvasókat, és kinyomtatja a csoportok létszámát.
DUPLIST - Duplikátumok megtalálásához.
Rendezett halmazt kell vele nyomtatni, és kiiírja azokat a tételeket,
amikből egynél több jött a rendezett halmazban egymás után. Pl.
földrajz rekordok név szerint rendezve. Igy meg lehet találni azokat,
amikből több azonos nevű is van.
Egyes rekordokról több mindent is kíír (földrajz, alkotó, példány),
a többiről csak a rendezési kulcsot.
A duplikátumok kezeléséhez készült azóta egy ennél jobb eszköz: Duplázódások megszüntetése. Ennek használatát javasoljuk inkább!
A nyomtató modulok által kinyomtatott szövegek tartalmát paraméterek megadásával módosítani lehet. Vannak pareméterek, amelyeket minden nyomtató modul megért, és vannak egy adott modulhoz tartozó paraméterek is.
| Paraméter | Mire jó |
|---|---|
| /SYS | minden rekord elé néhány sorba kiírja a rendszermezők (bevivő,módosítók,rendszer megjegyzés,...) tartalmát. |
| /BIBNO | a Bibliográfiai megjegyzés mezőt ne nyomtatassa |
| /PLDNO | a példányok adatait ne jelenítse meg a kötet előtt |
| /TEZNO | nem kellenek a tárgyszavak |
| /SZAKNO | szakcsoport és Cutter nem kell az elejére |
| /SZAKJOBB | szakcsoport és Cutter jobb oldalra igazítva |
| /SZAK2 | SZAKJELZET helyett a SZAKJELZET2 jelenjen meg |
| /OSZTNO | nem kellenek az osztályozások (ETO) |
| /TONO | nem kellenek a TO jelzetek |
| /TALPNO | egyáltalán nem kell a cédula talp |
| /BESORNO | besorolási adatok nem kellenek |
| /PLDVEG | példány adatok a cédula végén legyenek |
| /PLDALL | példány adatoknál az állomány is jelenjen meg |
| /MASTALP | a talpat más formában írja ki (Mt.,Ut.,Tft.) |
| /UKAZON | a cédula jobb felső sarkában megjelenik az UK azon |
| /ANAL | cédula aljára az analitikákat is kinyomtatja |
| /RENDSZO | rendszót generál |
| /KOZRE1 | a CIMADAT-beli közreműködőket nem nyomtatja |
| /RAKTJEL1 | a dok. elején a példány adatokból csak a rakt jelzetet, yomtatja ki (ha van, akkor az akt. jelzetet) |
| /RAKTJEL2 | mint az előző, de akt.rakt.jelzetet nem veszi figyelembe |
| /TORZSPLD | példány adatok más formában: leltszám: ár (raktjelzet)(akt.raktár: jelzet) |
| /KOZOSPLD | közös adat esetén minden kötetet minden példányának adatait a cédula elejére ki kell írni. |
| /ANALKIAD | analitika nyomtatásnál a forrás dokumentum megjelenési adatait is kiírja. |
| /KIEMELT | rendezett halmaz nyomtatása esetén kiírja a rendezési kulcsot a cédula előtt (csak amikor változik). |
| /SORALCIM | a sorozat alcime is jelenjen meg a cédulán |
| /SZAMOZ | sorszámozza a tételeket |
| /KOZTAURUSZ | a Köztauruaszt is kinyomtatja |
| /INTERNET | az Interneten mezőt is írja ki |
| Paraméter | Mire jó |
|---|---|
| /SZAKBAL | A szakcsoport és Cutter nem a jobb felső sarokban, hanem a bal oldalon jelenik meg. |
| /NAPRANE | Ne írja ki, hogy hány napra kölcsönözhető a könyv! |
| /VARHATO | Kiíródik, hogy mikorra várható vissza a könyv. |
| /MASHOLNEM | Csak a saját könyvtár példányait írja ki, beleértve a fiókok példányait is, a KSZR településieket nem. |
| /MASFIOKNEM | Csak a saját könyvtár példányait írja ki, a fiókok példányait nem. |
| /MASLISTA | A részletesen nem mutatott példányoknak csak a lelőhelyét listázza. |
| Paraméter | Mire jó |
|---|---|
| num | 0,1,2,3 lehet, kötelezően az első paraméter. A hivatkozó mezők részletezésének mélysége. |
| 0 | a rekord mezőit kinyomtatja, a hivatkozott rekordokat nem. |
| 1 | a rekord adatait kinyomtatja, a hivatkozott rekordokat is, de az onnan hivatkozottakat nem. |
| 2 | a rekord, hivatkozott rekordok, és az onnan hivatkozott rekordok nyomtatása. |
| /MEGJ | Rendszer megjegyzéseket is nyomtassa ki |
| /SYSALL | Minden rendszer mezőt nyomtasson |
| Paraméter | Mire jó |
|---|---|
| /SYS | minden rekord elé néhány sorba kiírja a rendszermezők (bevivő,módosítók,rendszer megjegyzés,...) tartalmát. |
| /HEADER | fejlécet nyomtat |
| /VONALKOD | kinyomtatja a vonalkódot is |
| /SZERZO | kinyomtatja a szerzőt (ha nincs, az első szerzőségi közlést) is |
| /AR | kinyomtatja a példány beszerzési árát is a leltári szám után |
| /OSSZAR | kiírja a kinyomtatott példányok árának összegét (és a példányok számát) |
| /SORSZAM | sorszámozza a tételeket |
| /TORL_JEGYZ | törlési jegyzék formátumban nyomtatja a listát |
| /LETETI | letéti lista formátumban nyomtatja a listát |
| /RAKTARI | raktári lista formátumban nyomtatja a listát |
| /ATHELYEZESI | áthelyezési lista formátumban nyomtatja a listát |
| /RAKTNO | nem nyomtat raktárt |
| /RAKTJELNO | nem nyomtat raktári jelzetet |
| /EVNO | nem nyomtatja ki a megjelenési évet |
| /KIEMELT | rendezett nyomtatáskor a rendezési kulcs minden változásakor kiemelt kulcsot nyomtat (pl: példányok állomány szerinti rendezése) |
| /CUTTER | kinyomtatja a szakcsoportot és a Cutter jelzetet |
| /EGYSOR | mindenképpen egyetlen sort nyomtat egy tételről |
| /BEKERULT | kinyomtatja az állomanybavétel dátumát |
| /SZALLITO | kinyomtatja a szállító nevét |
| /SZAMLASZAM | kinyomtatja a számlaszámot |
| /CSOPLELT | kinyomtatja a csoportos leltári számot |
| /FORRAS | kinyomtatja a beszerzési forrást |
| /KOLCS | kinyomtatja a példány kölcsönözhetőségét |
| /TELEPULES | kinyomtatja a könyvtárát (KSZR rendszer) |
| /DUPLASORTAV | dupla sortávolságot hagy |
| /LELTSZAM:nn | A leltársi szám milyen hosszban nyomtatódjon |
| /VONALKOD:nn | a vonalkód milyen hosszban nyomtatódjon |
| /RAKTJEL:nn | a raktári jelzetek milyen hosszban nyomtatódjon |
| /RAKTAR:nn | a raktár milyen hosszban nyomtatódjon |
| /CUTTER:nn | a Cutter milyen hosszban nyomtatódjon |
| /HATAROLO:X | X (pl. pontosvessző) legyen a mezők közti elválasztó. Ezt használjuk, ha excelbe akarjuk az adatokat betölteni. Pl.: /HATAROLO:; |
A TH_EGYEB paraméterei:
| Paraméter | mire jó |
|---|---|
| /TEZKAPCS | A tárgyszó rekordok kapcsolatait is kinyomtatja |
| Paraméter | Mire jó |
|---|---|
| /HATAROLO:X | X (pl. pontosvessző) legyen a mezők közti elválasztó. Ezt használjuk, ha excelbe akarjuk az adatokat betölteni. Pl.: /HATAROLO:; |
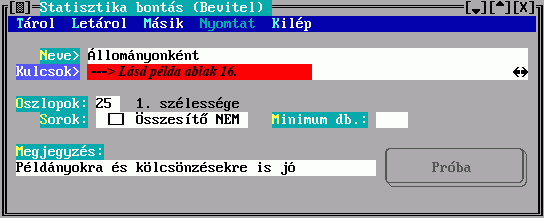
| /DB:N | Miniumum darabszám. Ha csak egyetlen rendezési kulcsot nyomtatunk, akkor számít. Csak a legalább N-szer előforduló kulcsokat írja ki (egyszer). |
Az OLVPRT paraméterei:
nincs paramétere
Az OLV_SZAM paraméterei:
nincs paramétere
A DUPLIST paraméterei:
| Paraméter | mire jó |
|---|---|
| /DREF | a rekordazonosítót írja ki a sor elejére |
| /URESKIIR | az <üres> szöveget írja ki, ha nem jött létre rendezési kulcs |
| /ZSAKBA | a kiírt dupla rekordokat a zsákba másolja |
| /SEMMI | csak a rekordazonsítót írja ki, a rendezési kulcsot nem |
A TextLib rendszerben a rendezést a találati halmazok (Lásd <halmaz.txt>!) nyomtatásánál használhatja. A rendezéshez állítson elő a halmazban felsorolt rekordokból az alábbi leírás szerint besorolási adatokat és besorolási tételeket, azokat a rendszer egy rendezési tábla használatával sorba állítja. Ily módon a bibliográfiai tételek betűrendbe sorolásának szabályait meghatározó MSZ 3401-81 szerinti rendezést végezhet el. (Kivétel az összetett családnevet tartalmazó besorolási adat, ebben a családnév nem egy besorolási elem, hanem több.)
A rendezési formátumok előállítását csak a rendszergazdától erre jogot kapott könyvtárosok végezhetik el.
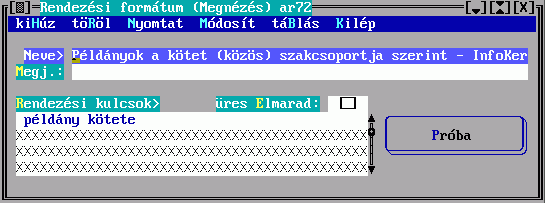
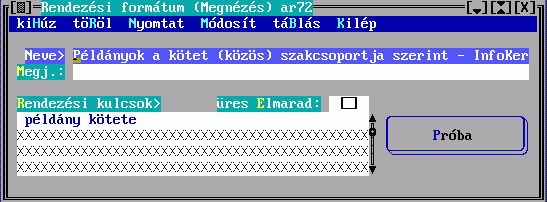
Korábban elkészített rendezési formátumot kereshet meg az alábbi űrlap használatával:
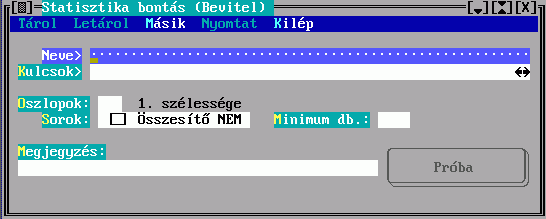
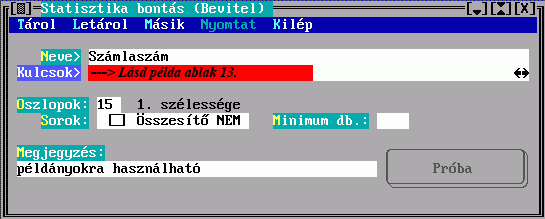
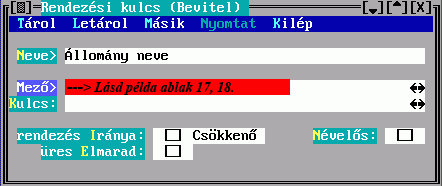
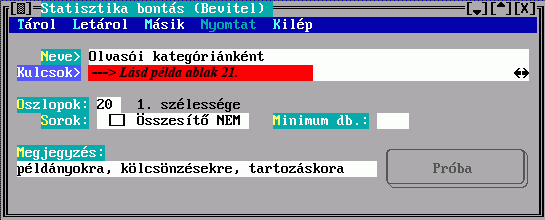
A besorolási tételek előállításának szabályait a rendezési formátumban meghatározandó rendezési kulcsok adják meg:
A rendezési formátum neve alapján hivatkozhat majd egy halmaz nyomtatásánál a rendezés szabályaira, megjegyzésként tetszőleges magyarázatot fűzhet hozzá. A rendezési kulcs egy besorolási adat képzésének szabályát írja le, egy besorolási tétel több besorolási adatból -rendezési kulcsból- állhat össze:
A név a rendezési formátumban mutatja, hogy milyen besorolási adatokból épül fel a tétel, a besorolási adat előállítási módját pedig a Mező vagy a Kulcs kitöltésével írhatja elő. Egy besorolási adat képzéséhez csak az egyiket választhatja, és gondoskodnia kell arról, hogy a találati halmazban szereplő esetleg különböző rekordok mindegyikére legyen szabály. E helyre tehát egy lista kerülhet, ami a besorolási tétel soron következő besorolási adatának képzési szabályát adja meg a halmaz minden rekordtípusára. Amennyiben a halmaz valamelyik rekordjáról több leírást is készít, csak az első lesz érvényes.
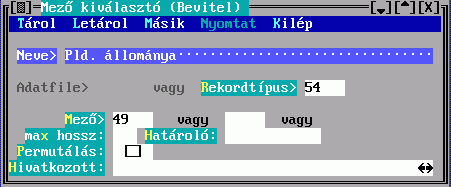
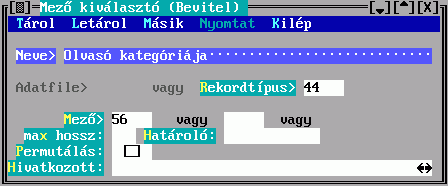
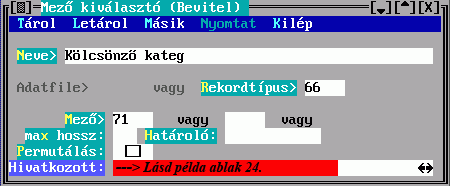
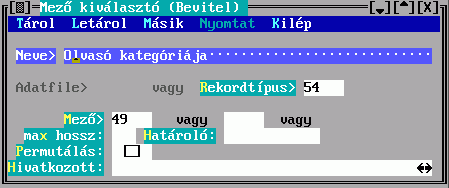
A Mező kitöltésekor a rendezendő rekord egy mezejének karaktersorozattá alakításáról nyilatkozhat, a Kulcs kitöltésekor több mezőből készül egy karaktersorozat. Ezek részleteit a Mező kiválasztó illetve a Kulcskészítés című ablakban írhatja le.
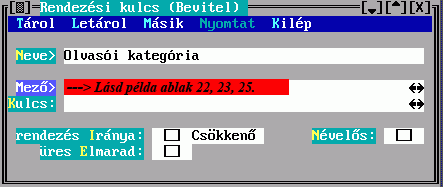
A besorolási adatok kezelését három mező kitöltésével befolyásolhatja:
Ha a rendezés Iránya Csökkenő mezőt megjelöli, akkor növekvőből csökkenővé változik az aktuális besorolási adatra nézve. Elérheti tehát, hogy az egymás után következő besorolási adatok ellentétes irányba rendeződjenek.
Ha egy tétel valamelyik besorolási adata hiányzik (pl. szerző nélküli
dokumentum), a TextLib az üres besorolási adatot előre sorolja. Az üres
Elmarad mező megjelölésével ez megváltozik, az üres helyére csúszik az utána
következő besorolási adat (pl. a dokumentum címe).
Ha üres Elmarad jelöletlen:
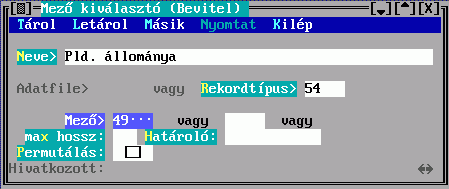
A rendezendő rekord egy mezejének karaktersorozattá alakítását szabályozhatja az alábbi adatlap kitöltésével:
Az Adatfájl és a Rekordtípus közül csak az egyiket adhatja meg, ez megszabja, hogy a találati halmaz mely adatfájlhoz vagy rekordtípushoz tartozó elemeiből készüljön e leírás szerint besorolási adat. Mindkettőre a DBSTRUCT-ból kiolvasható sorszáma alapján hivatkozhat.
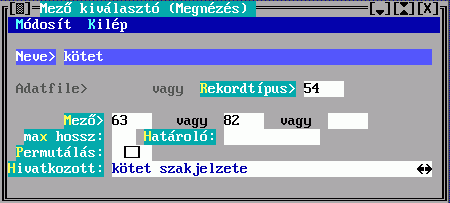
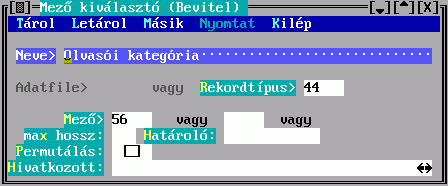
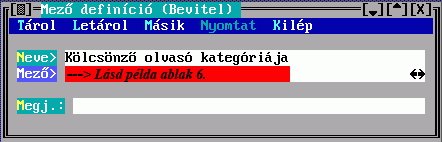
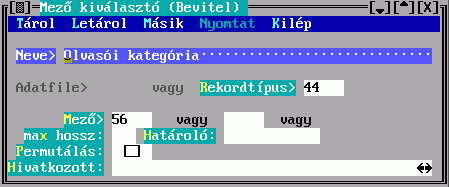
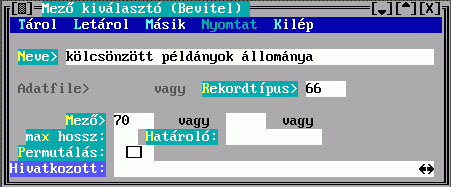
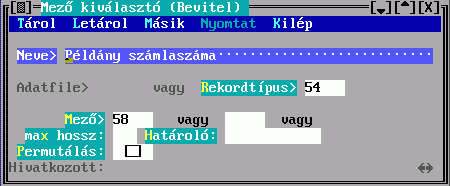
A Mező tartalmából készül a besorolási adat karaktersorozata. Hármat adhat meg, az első nem üres fog megjelenni. Ha van közöttük hivatkozó mező, akkor megadható a Hivatkozott, amiben egy ugyanilyen Mező kiválasztó űrlapon leírhatja a hivatkozott rekord megjelenítésének szabályát. Ha nem adja meg, akkor beépített mechanizmus szerinti, úgynevezett főmezős megjelenítés történik. A mezősorszámokat DBSTRUCT segítségével találja meg.
A megadott mezők között lehet ismételhető is. A Permutálás mező megjelölése eredményeként az összes ismétlődés szerint készül besorolási adat, tehát a besorolási tételek száma is sokszorozódik. Ellenkező esetben csak az első ismétlődés jelenik meg. Pl. ha szerzők és ezen belül kiadók szerint kell rendezni, és van 5 szerző és 4 kiadó, akkor 20 (megjelölt Permutálás) illetve 1 (megjelöletlen) besorolási tétel képződik.
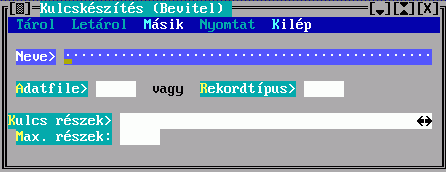
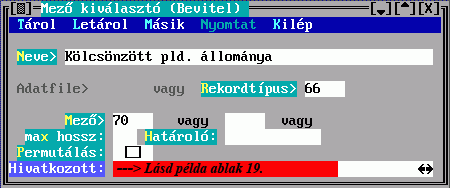
Több mezőből egy besorolási adat
A rendezendő rekord több mezejének egy karaktersorozattá alakítását szabályozhatja az alábbi adatlap kitöltésével:
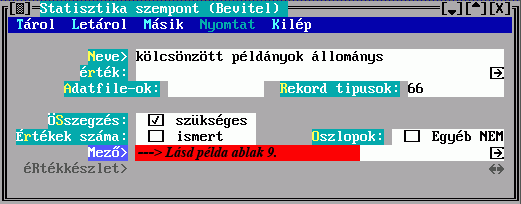
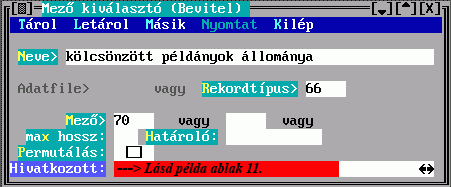
Az Adatfájl és a Rekordtípus közül csak az egyiket adhatja meg, ez megszabja, hogy a találati halmaz mely adatfájlhoz vagy rekordtípushoz tartozó elemeiből készüljön e leírás szerint besorolási adat. Mindkettőre a DBSTRUCT-ból kiolvasható sorszáma alapján hivatkozhat.
A Max. részek mezőbe írt érték korlátozza az egy besorolási adat összeállításához felhasználható részek számát.
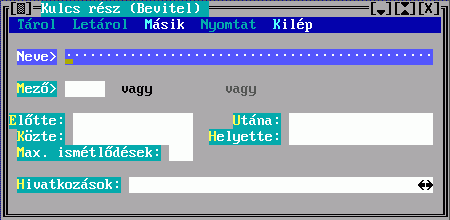
A kulcskészítéshez kulcsrészek leírását kell elkészíteni:
A kulcskészítéshez használható kulcsrészek leírása a mező kiválasztáshoz hasonlóan folyik.
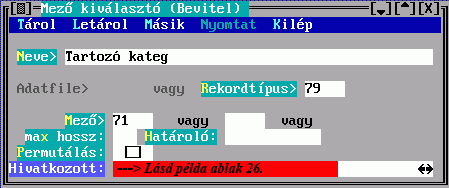
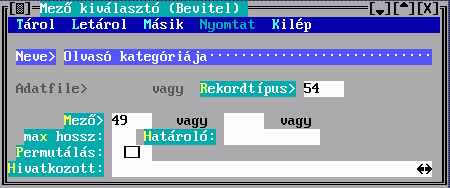
A Mező tartalmából készül a besorolási adat karaktersorozatának egy része. Hármat adhat meg, az első nem üres fog megjelenni. Ha van közöttük hivatkozó mező, akkor a Hivatkozások megadására a fenti Kulcskészítés űrlapon kerül sor. Ha nem adja meg, akkor beépített mechanizmus szerinti, úgynevezett főmezős megjelenítés történik. A mezősorszámokat DBSTRUCT segítségével találja meg.
A megadott mezők között lehet ismételhető is. Az elkészülő besorolási adatrészben az ismétlődésszámot a Max. ismétlődések mező kitöltésével szabályozhatja, ennek hiányában az összes ismétlődés bekerül.
Az Előtte, Utána és Közte konstans szöveget tartalmazhat, ami a mezőből keletkezett szöveg előtt, után, illetve az ismétlődések között jelenik meg.
A Helyette mezőbe írt szöveg fix része lesz egy besorolási adatnak, ha egyetlen mezősorszámot sem tölt ki.
Megjegyzés
A rendezési helyettesítési jelek (lásd bill.txt!) használatával tudja módosítani a rendezést azokban az esetekben, amikor a helyes mezőtartalom helytelen rendezési sorrendet eredményez. Ilyen lehet pl. a római számok vagy a betűvel leírt számok esete. Rendezési helyettesítési jelek használatával leírhatja a módosítani kívánt szövegrész rendezési helyettesítőjét:
{XX=20}. század
{Első=1} kötet
{Második=2} kötet
{Harmadik=3} kötet
A példa egy olyan rendezési formátum elkészítését tartalmazza, amelyben a rendezés kulcsai a kötet szerzője, címe és kiadási éve. A szabadalom típusú dokumentumnál a SZERZO helyett a TULAJDONOS szerepel, a cím többkötetes mű esetén tartalmazza a közös címet és a kötetjelzést is. Rendezési formátum készítésére csak akkor van módja, ha kapott jogot a rendszergazdától.
| Neve: | Név |
|---|---|
| rendezés Iránya: | jelöletlen |
| üres Elmarad: | megjelölt |
| Névelős: | jelöletlen |
| A "Mező" mezőben válasszon beszúrást, így a "Mező kiválasztó" ablakba jut! | |
| Neve: | Szerző neve |
| Rekordtípus: | 53 (DOKUMENTUM) |
| Mező | 70 (SZERZO) |
| Permutálás: | megjelölt |
| Neve: | Tulajdonos neve |
|---|---|
| Adatfájl: | 110 (SZABKOT) |
| Mező: | 113 (TULAJDONOS) |
| Permutálás: | megjelölt |
| Neve: | Közös cím - kulcs |
|---|---|
| rendezés Iránya: | jelöletlen |
| üres Elmarad: | megjelölt |
| Névelős: | megjelölt |
| A "Mező" mezőben válasszon beszúrást, így a "Mező kiválasztó" ablakba jut! | |
| Neve: | Közös cím - mező a közöshöz |
| Rekordtípus: | 53 (DOKUMENTUM) |
| Mező: | 89 (DOK) |
| Permutálás: | jelöletlen |
| Neve: Közös cím - mező a közösben | |
|---|---|
| Rekordtípus: | 53 (DOKUMENTUM) |
| Mező: | 48 (FOCIM), 50 (PARHUZAMOSCIM), 52 (CIMADAT) |
| Permutálás: | jelöletlen |
| Neve: | Kötetjelzés - kulcs |
|---|---|
| rendezés Iránya: | jelöletlen |
| üres Elmarad: | megjelölt |
| Névelős: | megjelölt |
| A "Mező" mezőben válasszon beszúrást, így a "Mező kiválasztó" ablakba jut! | |
| Neve: | Kötetjelzés - mező |
| Rekordtípus: | 53 (DOKUMENTUM) |
| Mező: | 88 (RESZJELZES) |
| Permutálás: | jelöletlen |
| Neve: | Cím - kulcs |
|---|---|
| rendezés Iránya: | jelöletlen |
| üres Elmarad: | megjelölt |
| Névelős: | megjelölt |
| A "Mező" mezőben válasszon beszúrást, így a "Mező kiválasztó" ablakba jut! | |
| Neve: | Cím - mező |
| Rekordtípus: | 53 (DOKUMENTUM) |
| Mező: | 48 (FOCIM), 50 (PARHUZAMOSCIM), 52 (CIMADAT) |
| Permutálás: | jelöletlen |
| Neve: | Kiadási év - kulcs |
|---|---|
| rendezés Iránya: | jelöletlen |
| üres Elmarad: | megjelölt (nincs jelentősége) |
| Névelős: | jelöletlen |
| A "Mező" mezőben válasszon beszúrást, így a "Mező kiválasztó" ablakba jut! | |
| Neve: | Kiadási év - mező |
| Rekordtípus: | 53 (DOKUMENTUM) |
| Mező: | 49 (MEGJEVE) |
| Permutálás: | jelöletlen |
A kiadvány készítés alatt egy olyan nyomtatást értünk, ahol a (valamilyen szempont szerint rendezett) tételek nyomtatása után még egy vagy több index is generálódik, és ezek is kinyomtatódnak. A kinyomtatott tételek egyedi sorszámmal vannak ellátva, az indexben erre való hivatkozás történik.
A kiadvány készítése egy előre létrehozott találati halmazzal történhet.
Kiadvány formátumot a rendszergazda definiálhat (és azok a dolgozók, akiknek ehhez ő jogot ad). Kiadvány formátumot a rendszergazda a Rendszer / rendszerelemek Bevitele / kiAdvány formátum menüpontból indulva adhat meg. A többi dolgozó (a rendszergazda is) a kiadvány készítés indítása után feltűnő ablakban a Formátum> mezőbe beszúrással.
A kiadvány formátum definiálása nagyon hasonlít a nyomtatási formátum definiálásához. (Lásd:nyform.txt) Annyival több annál, hogy definiálni kell az indexek készítéshez és nyomtatásához szükséges dolgokat. Itt most csak azokat a részeket ismertetjük, amik a nyomtatási formátumnál nem szerepeltek.
Indexelő modul mezőben annak a modulnak a nevét kell megadni, ami az indexeket készíti el. Ilyen jelenleg csak egy van (INDEXGEN), de hamarosan definiálhatóvá tesszük az indexek generálását az output nyelv segítségével.
Index kiíró modul mezőben az indexeket kiíró modul nevét kell megadni. Egyelőre ebből is csak egy van (INDEXPRT), de ez is definiálható lesz.
Mindkét előbb említett modulnak adhatók Paramétetek.
Az INDEXGEN modul a következőket kezeli (ha semmit nem adunk meg, akkor csak egy közös index készül):
| Paraméter | mire jó |
|---|---|
| /CIM | készül külön cím index |
| /SZERZO | készül külön szerző index |
| /TARGYSZO | készül külön tárgyszó index |
| /KOZOSNEM | ne készüljön közös index |
| /ANAL | az dokumentum analitikáiba is belemegy, abból is készül index Ha itt megadjuk, akkor érdemes a nyomtató modul paraméterei közt is megadni, hogy ki is nyomtatódjanak az analitikák. |
Az index nyomtatásakor más hasábszám használható, mint a tételek nyomtatásakor. Ezt az index Hasábok mezőben lehet megadni.
Megjegyzés: a Fölötte mezőben ne felejtsünk el megadni valami szöveget, ami tartalmazzza a % jelet, különben nem lesznek sorszámok nyomtatva a tételek előtt, és ilyenkor az index (ami a tételszámokra hivatkozik) elég nehezen használható.
Kiadvány készítés
A kiadvány készítést minden dolgozó az Egyéb / kiAdvány készítés menüpontból érheti el.
Az ablak művelet mezőjében mindig láthatjuk, hogy mi történuk éppen. Kezdetben ez adatmegadás-t mutat.
Először meg kell adnunk azt a Halmaz-t, amit használni akarunk. A lokális menüből a Beszúrás menüponttal (F9) választhatunk a meglevő halmazok közül.
A Formátum mezőbe a kiadvány formátum kerül. Itt is F9-re kapunk listát a meglévő kiadvány formátumokról. Azoknak a dolgozóknak, akiknek joguk van kiadvány formátum bevitelére, az expand ablakban látszik a Bevitel gomb is.
Amelyik mezőt már kitöltöttük, azt meg lehet részletezni (ALT/F9). A Halmaz esetében a halmaz elemeit tekinthetjük meg, a Formátum-nál pedig a kiadvány formátum adatait. Ha olyan dolgozó teszi ezt, akinek van joga változtatni a kiadvány formátumokon, az tud módosítani is.
A mezők kitöltése után (ekkor a művelet mezőben az 'indítható' szöveg jelenik meg) használhatóvá válik a Rendben gomb, amivel el lehet indítani a a kiadvány készítést. Ekkor először a nyomtató állapot ablak tűnik fel. Ebben kell beállítani, hogy hova és hogyan akarunk nyomtatni. Ez a beállítás a kiadvány készítés sajátja, a rendszerben egyébként is meglevő nyomtató beállítást nem befolyásolja.
Ebben az ablakban mindig az a default beállítás, hogy fájlba akarunk nyomtatni, és nem akarunk mustrát. Ezt természetesen meg lehet változtatni. Ha az ablakból a Mégsem gombbal lépünk ki, természetesen nem megy tovább a kiadvány készítés. Ellenkező esetben azonban elindul.
Ha fájlba irányul a nyomtatás, akkor az első teendő, hogy meg kell adnunk a fájl nevét. Ha ezen túlvagyunk (és nem kértünk mustrát), akkor a művelet mezőben követhetjük, hogy hol tart a program. Itt először a 'rendezés' szöveg jelenik meg. Ha elkészült a rendezett halmaz (és nem 0 elemű), akkor következik a 'nyomtatás'. Ha ez is elkészült, akkor az 'index készítés' következik. Az 'index nyomtatás' után pedig megjelenik a 'Kész' üzenet.
Ha menet közben ki akarunk lépni, a program rákérdez:
Kiadvány formátumot direktben (nem kiadvány készítés közben) keresni csak a rendszergazda tud, a Rendszer / Rendszer adatok keresése / kiAdvány formátum menüponttal:
Az általunk készített index generáló modul az INDEXGEN többféle indexet is tud gyártani. Közöset, cím szerintit, szerző szerintit, tárgyszó szerintit. Ezek közül a közös index az, ami nem egészen egyértelmű. Ebbe az indexbe a következő alakú bejegyzések kerülnek:
szerző_egységes_név. cím -> tételszám szerző_egységes_név. egységes_cím. cím -> tételszám cím / szerző_egységes_név -> tételszám egységes_cím. cím / szerző_egységes_név -> tételszám közreműködő_egységes_név (funkció) -> tételszám *tárgyszó -> tételszám szerző_névváltozat -> szerző_egységes_név közreműködő_névváltozat -> közreműködő_egységes_név
A TextLib rendszerben lehetőség van a keresőnyelv használatára. Ennek segítségével lehet azokat a bonyolult kérdéseket megfogalmazni, amiket az ablakos keresésben már nem lehetett feltenni. A nyelv lehetőséget ad keresésre az indexeken, halmazok projektálására, szűkítésére, valamint lehetővé teszi halmazműveletek elvégzését is.
A TextLib rendszerben lehetőség van a keresőnyelv használatára. Ennek segítségével lehet azokat a bonyolult kérdéseket megfogalmazni, amiket az ablakos keresésben már nem lehetett feltenni. A nyelv lehetőséget ad keresésre az indexeken, halmazok projektálására, szűkítésére, valamint lehetővé teszi halmazműveletek elvégzését is.
A keresőnyelven megírt programokat - nevezzük ezeket keresőkérdésnek - el lehet tárolni, legközelebb betölteni, szerkeszteni, futtatni. Minden felhasználónak lehetnek saját keresőkérdései. Ezen kívül lehetőség van arra is, hogy a rendszergazda definiáljon olyan keresőkérdéseket, amiket mindenki fel tud használni.
A keresőkérdés helyettesítheti a projekciót. Definiálhatunk ugyanis olyan keresőkérdést, aminek egyetlen paramétere van, egy halmaz. Az ilyen keresőkérdést használhatjuk projekcióként.
Szinte mindenkinek (olvasó, könyvtáros, rendszergazda) a főmenüjében a Keresés menüpont alatt megtalálhatók a következő menüpontok, amiknek a segítségével a keresőkérdéseket kezelheti:
Ebben az ablakban a felhasználó a saját keresőkérdéseit szerkesztheti, futtathatja, elmentheti és betöltheti:
Az egyes menüpontok jelentése:Sok olyan keresőkérdés lehet, amire mindenkinek szüksége van. A rendszergazdának lehetősége van arra (Rendszer/Bevitel/Keresőkérdés menüpont), hogy ilyeneket definiáljon, és ezeket minden könyvtáros és olvasó használhassa.
A keresés/kész Kérdések menüpont kiválasztása után megjelenik az alábbi ablak:
Ugyanakkor megjelenik egy másik ablak, amiben a keresőkérdések közül választhatunk. Ha nem választunk semmit, mindkét ablak eltűnik. Ha választottunk, akkor az első ablak megmarad.Ha a kérdés tartalmaz paramétereket, akkor megjelenik egy ablak, amiben a paraméterek értékeit kell megadni. Ha a keresőkérdés tartalmaz NEVEZD utasításokat, akkor a paraméter megadásakor még expand-ot is lehet kérni.
Ha a keresés sokáig tart, akkor a képernyő alsó sorában kapunk információt arról, hogy hány tételt nézett már végig a program, és ebből hány találat képződött.
Ha elindítottuk a keresést, de még nem ért véget, akkor a Kilép menüpont kiválasztásával tudjuk abbahagyni a keresést. Természetesen rákérdez a program, hogy valóban ezt akarjuk-e csinálni.
A rendszergazda a kersőkérdés bevitelekor igazából két dolgot is definiálhat: keresőkérdést vagy projekciót (esetleg mindkettőt egyszerre). A projekció ezentúl a keresőkérdés egy speciális esete lesz, az az eset, amikor éppen egy paramétere van a keresőkérdésnek, és az egy halmaz. (pl: SZUKITS kotet es dok &%1).
A keresőkérdést a következő ablakban lehet megadni:
Neve: Ebben a mezőben kell megadni azt a nevet, amit a keresőkérdés nevének szánunk. Ha olyan keresőkérdést csinálunk, amit csak projekciónak akarunk használni, akkor üresen lehet hagyni.Proj.név: Ha projekciónak is akarjuk használni a keresőkérdést, akkor ezt a mezőt kell kitölteni. Ha ezt a mezőt kitöltjük, akkor csak olyan keresőkérdést fogad el a program, amiben csak egy darab halmaz paraméter szerepel.
Olv.név: Az olvasó ezen a néven fogja látni a keresőkérdést. Ha üresen hagyjuk, akkor egyáltalán nem fogja tudni használni.
A két mező közül legalább az egyiket ki kell tölteni, e nélkül nem lehet a keresőkérdést tárolni.
Keresőkérdés: Ebbe a mezőbe kell beírni a keresőkérdést. Tárolás előtt ez mindig lefordítódik, és csak akkor lehet tárolni, ha nincs benne hiba.
Próba A gomb megnyomására a program lefordítja a keresőkérdést, és ha nem volt benne hiba, akkor le is futtatja. Ha voltak találatok, akkor megjelenik a találati halmaz. A halmaz megnézéséből kilépve ez a halmaz automatikusan törlődik is.
A keresőnyelven megírt programokat - nevezzük ezeket keresőkérdésnek - el lehet tárolni, legközelebb betölteni, szerkeszteni, futtatni. Minden felhasználónak lehetnek saját keresőkérdései. Ezen kívül lehetőség van arra is, hogy a rendszergazda definiáljon olyan keresőkérdéseket, amiket mindenki fel tud használni.
A keresőkérdés helyettesítheti a projekciót. Definiálhatunk ugyanis olyan keresőkérdést, aminek egyetlen paramétere van, egy halmaz. Az ilyen keresőkérdést használhatjuk projekcióként.
Szinte mindenkinek (olvasó, könyvtáros, rendszergazda) a főmenüjében a Keresés menüpont alatt megtalálhatók a következő menüpontok, amiknek a segítségével a keresőkérdéseket kezelheti:
Ebben az ablakban a felhasználó a saját keresőkérdéseit szerkesztheti, futtathatja, elmentheti és betöltheti:
Az egyes menüpontok jelentése:Sok olyan keresőkérdés lehet, amire mindenkinek szüksége van. A rendszergazdának lehetősége van arra (Rendszer/Bevitel/Keresőkérdés menüpont), hogy ilyeneket definiáljon, és ezeket minden könyvtáros és olvasó használhassa.
A keresés/kész Kérdések menüpont kiválasztása után megjelenik az alábbi ablak:
Ugyanakkor megjelenik egy másik ablak, amiben a keresőkérdések közül választhatunk. Ha nem választunk semmit, mindkét ablak eltűnik. Ha választottunk, akkor az első ablak megmarad.Ha a kérdés tartalmaz paramétereket, akkor megjelenik egy ablak, amiben a paraméterek értékeit kell megadni. Ha a keresőkérdés tartalmaz NEVEZD utasításokat, akkor a paraméter megadásakor még expand-ot is lehet kérni.
Ha a keresés sokáig tart, akkor a képernyő alsó sorában kapunk információt arról, hogy hány tételt nézett már végig a program, és ebből hány találat képződött.
Ha elindítottuk a keresést, de még nem ért véget, akkor a Kilép menüpont kiválasztásával tudjuk abbahagyni a keresést. Természetesen rákérdez a program, hogy valóban ezt akarjuk-e csinálni.
A rendszergazda a kersőkérdés bevitelekor igazából két dolgot is definiálhat: keresőkérdést vagy projekciót (esetleg mindkettőt egyszerre). A projekció ezentúl a keresőkérdés egy speciális esete lesz, az az eset, amikor éppen egy paramétere van a keresőkérdésnek, és az egy halmaz. (pl: SZUKITS kotet es dok &%1).
A keresőkérdést a következő ablakban lehet megadni:
Neve: Ebben a mezőben kell megadni azt a nevet, amit a keresőkérdés nevének szánunk. Ha olyan keresőkérdést csinálunk, amit csak projekciónak akarunk használni, akkor üresen lehet hagyni.Proj.név: Ha projekciónak is akarjuk használni a keresőkérdést, akkor ezt a mezőt kell kitölteni. Ha ezt a mezőt kitöltjük, akkor csak olyan keresőkérdést fogad el a program, amiben csak egy darab halmaz paraméter szerepel.
Olv.név: Az olvasó ezen a néven fogja látni a keresőkérdést. Ha üresen hagyjuk, akkor egyáltalán nem fogja tudni használni.
A két mező közül legalább az egyiket ki kell tölteni, e nélkül nem lehet a keresőkérdést tárolni.
Keresőkérdés: Ebbe a mezőbe kell beírni a keresőkérdést. Tárolás előtt ez mindig lefordítódik, és csak akkor lehet tárolni, ha nincs benne hiba.
Próba A gomb megnyomására a program lefordítja a keresőkérdést, és ha nem volt benne hiba, akkor le is futtatja. Ha voltak találatok, akkor megjelenik a találati halmaz. A halmaz megnézéséből kilépve ez a halmaz automatikusan törlődik is.
Az általános statisztika segítségével egy tetszőleges módon előállított halmaz elemeire készíthetünk (két dimenziós) statisztikákat. Megadhatjuk, hogy mik legyenek a statisztika oszlopai, és sorai.
A statisztika használata igen egyszerű, ellentétben a statisztikai szempontok, és bontások definiálásával. Ez utóbbiakat természetesen csak a rendszergazda végezheti.
Az általános statisztika készítésekor felhasználhatjuk az állomány statisztikai (lásd: <all_stat>) szempontokat is. Fordítva ez természetesen nem érvényes.
A főmenü Egyéb/sTatisztika menüpontjának kiválasztásakor az alábbi alakú képernyőn adhatók meg az igényelt statisztika paraméterei:
A statisztika készítés eredménye mindig eltárolódik. Ahhoz, hogy ezeket később újra elő tudjuk venni, a Név mezőt ki kell töltenünk. Használható az expand (F9) is a kész statisztikák neveinek megtekintéséhez.Ha olyan nevet adunk meg, ami már létezik, akkor azt az eredmény rekordot betölti. Ezt ki tudjuk nyomtatni, akár különbözö paraméterekkel is. Az Eredmény: mezőt részletezve megnézhetjük a statisztika rekordot, és változtathatunk is rajta, ami a nyomtatásra is hatással van. Törölhetjük is, ha már nincs rá szükség.
A következő mezők változtatása a nyomtatást befolyásolja:Egyéb NEM mező: Elhagyandó az EGYÉB oszlop. A statisztika rekordban mindig benne van, csak kinyomtatni nem kell.
Oszlopok: 1. szélessége mező: Az első oszlop szélessége megadható. Ha pl. könyvcímeket tartalmaz, akkor érdemes nagyobbra venni, mint a default 20 karakter.
Sorok: Összesítő NEM mező: Megadható, hogy kell-e az egyes kiemelt tételek után összesítő sor. Ha kipipáljuk ezt a mezőt, akkor minden statisztika sor valóban egyetlen sor lesz (nem kettő, ami a default).
Minimum db.: mező: Megadható minimum darabszám. Csak azok a sorok nyomtatódnak, amikben ennél több a kiírt oszlopokba kerülő értékek összege. Ennek igazából csak akkor van értelme, ha az EGYÉB oszlopot elhagyjuk, mert ha nem, akkor minden sorban pontosan ugyanannyi az oszlopok osszege.
Ha nincs még az adott néven készült statisztika, akkor kell csak megadnunk a következő mezőket:
A statisztika a következő formában nyomtatódik (például egy 'Nyelv' szempont szerinti lista, állományok szerinti bontásban):
Név: Központi raktár példányai
Szempont: Nyelv
Bontás: Állomány
Halmaz: H2 [ 90] Raktar=Központi
Készült:1998-10-27, Nyomtatva:1998-10-27
Nulla értékű példány: 3 db
| angol |francia| német | orosz |spanyol| Egyéb |Összes |
| | | | | | | |
{üres} | 0 | 2 | 1 | 0 | 0 | 0 | 3 |
| 0 | 198 | 199 | 0 | 0 | 0 | 397 |
Felnőtt | 0 | 4 | 2 | 2 | 1 | 15 | 24 |
| 0 | 638 | 999 | 198 | 234 | 2478 | 4547 |
Gyermek | 1 | 7 | 4 | 1 | 2 | 20 | 35 |
| 0 | 1359 | 967 | 99 | 468 | 4652 | 7545 |
Központi | 2 | 0 | 3 | 3 | 0 | 20 | 28 |
| 123 | 0 | 792 | 297 | 0 | 3858 | 5070 |
| 3 | 13 | 10 | 6 | 3 | 55 | 90 |
egyenleg | 123 | 2195 | 2957 | 594 | 702 | 10988 | 17559 |
Az elején az a név jelenik meg, amit a statisztika készítéskor megadtunk. Ezt követi a készítés és nyomtatás dátuma, a szempont (Nyelv) és a bontás (Állomány).
A statiszika minden sora igazából két sor. Az első példányszám, a második pedig a szempont definíciójánál megadott mező értékek összege (pl: példány árak). A második sor elhagyható, ha a statisztika eredmény rekordban, vagy a statisztika készítés előtt a statisztika bontás rekordban az Sorok: [ ] Összesítő NEM mezőt kipipáljuk.
A statisztika nyomtatása 160 oszlopos és 18 soros lapokra történik. Ha a statisztika szélessége még ennél is nagyobb, akkor a sorok törnek. File-ba nyomtatás után a megtört sorokat egy tetszőleges editorban egyberagasztva kaphatjuk meg a teljes táblázatot (amit kinyomtatni nem fogunk tudni, legfeljebb darabokban).
A statisztika szempontjait a rendszergazda definiálja a főmenü Rendszer / rendszerelemek Bevitele / Statisztikai szempont menüpontjának választásával:
A Neve mezőben értelemszerűen a szempont nevét kell megadni (pl. dokumentumtípus, nyelv, kiadási év, olvasói kategória, stb). Ezzel a névvel lehet majd a szempontra a statisztika készítésekor hivatkozni.
Az éRték mezőben adhatjuk meg, hogy mit kell a statisztika számítás során összegezni. Ha itt nem adunk meg semmit, akkor csak a rekordok számlálása történik meg; példányok esetében a mező alapértelmezett értéke a beszerzési ár.
A statisztika definiálásakor lehet megadni azt is, hogy milyen rekordokra van értelmezve a statisztika. Egy olvasókat számláló statisztikát készíteni példány rekordokból álló halmazon nem lenne túl szerencsés. Az Adatfájlok és Rekord típusok mezőkben sorolhatjuk fel, hogy milyen rekordokra van értelmezve a statisztika. Ha egyik mezőben sem adunk meg semmit, akkor PELDANY rekordtípust tételez fel a program.
Ha az ÖSszegzés mezőt bejelöljük, a statisztika készítésekor az adott szempont szerinti statisztika sorainak végén a szempont egyes értékei után egy "Összes" fejlécű oszlopban a sorösszeg is kinyomtatásra kerül.
Ha az Értékek Száma ismert, a Mező mező nem értelmezett. Kötelező viszont az ÉrtékKészlet. Itt kell megadni a szempont értékeit, azt az ismert, véges számú osztályt, amelybe az adott szempont szerint sorolni lehet a példányokat. Ilyen szempont például a "dokumentumtípus" vagy a "tartalom fő jellege", általánosságban minden olyan szempont, ahol előre ismert számú és értékű lehetséges értéke van a szempont szerinti osztályozásnak.
Ha az Értékek Száma nem ismert (ilyen pl. a szállító, a nyelv vagy a kiadási év) az ÉrtékKészlet mező nem értelmezett. A Mező viszont kötelező. Ennek megadásával a szemponthoz asszociált mezőt, azaz azt a mezőt kell ilyenkor specifikálni, ami alapján a besorolás történik.
Ha a Mező vagy az Értékkészlet mezők egyikét kitöltöttük, akkor az Értékek száma mezőt már nem tudjuk változtatni. Ha mégis ezt akarjuk, akkor az előbb említett mezők tartalmát ki kell törölni.
Mező definiálása
Lásd: <mezodef>
Értékkészlet definiálása
Lásd: <ertkeszl>
Statisztika bontás definiálása
Lásd: statbont
Példák statisztika szempontok definiálására
a. Olvasói kategória
Ha az olvasókat akarjuk kategóriák szerint megszámolni, akkor jön jól egy ilyen statisztika.
b. Kölcsönző olvasó kategóriájaHa a kölcsönzéseket akarjuk olvasói kategóriák szerint megszámolni, akkor érdemes egy ilyen szempontot készíteni:
c. Kölcsönadott példány állományaHa a kölcsönzéseket akarjuk a példányok állománya szerint megszámolni, akkor érdemes egy ilyen szempontot készíteni:
Definiálhatók statisztika bontási szempontok is. Ezek segítségével szabályozhatjuk, hogy a statisztika egyes soraiba mi kerüljön. Definiálhatunk pl. "Állományonként", "Számlaszám", "Törl.jegyz", "Raktár" nevű bontást. De készíthetünk két 'mélységű' bontást is, pl: "Állomány/számlaszám" néven.
A statisztika bontás definiálása szinte teljesen megegyezik a rendezési formátum (lásd: rendezes) definiálásával. Itt is az a feladat, hogy megadjuk: egy rekordhoz mi módon kell elkészíteni a bontási (rendezésnél: rendezési) kulcsot. Pl: az "Állományonként" nevű bontásnál egyszerűen a példány rekorodok Állomány mezőjet kell megadni.
A statisztika készítéskor a statisztika sorai pontosan azok lesznek, amik a bontás alkalmazásakor előállnak (pl: az "Állományonként" bontásnál az állományok nevei).
A statisztika szempontjait a rendszergazda definiálja a főmenü Rendszer / rendszerelemek Bevitele / Statisztika bontás menüpontjának választásával:
A Neve mezőben megadott névvel lehet majd a bontásra a statisztika készítéskor hivatkozni.A bontási Kulcsok általában egyetlen elemet tartalmaz, ami azt adja meg, hogy mik lesznek a statisztika egyes sorai. Megadhatunk két kulcsot is (pl: Állomány, Számlaszám), ilyenkor az első kulcsokat kiemelten kezeli a statisztika nyomtatás (külön sorban jeleniti meg), és a második kulcsokból képződnek a statisztika sorai. Ezzel a módszerrel készíthető pl. lista Állományok szerinti bontásban a számlaszámokról.
Az Oszlopok: 1. szélessége mezőben az első oszlop szélességét adhatjuk meg, ha nem felel meg a default 20 karakteres szélesség.
A Sorok: Összesítő NEM mező kitöltése esetén az elkészült statisztika nyomtatásakor az összesítő sorok nem nyomtatódnak ki. Ezt a kész statisztika rekord változtatásával később is módosíthatjuk, mivel ugyanez a mező megvan abban is.
A Minimum db.: mezőben azt adhatjuk meg, hogy csak azok a sorok nyomtatódjanak ki, amikben a kinyomtatandó oszlopokba került értékek összege legalább ennyi. Ennek főleg akkor van értelme, ha az EGYÉB oszlop elhagyását kértük nyomtatáskor.
Ha van már egy korábban lekeresett halmazunk, a Próba gomb megnyomásával megtekithetjük, hogy milyen kulcsok képződnek az egyes rekordokból. Ily módon gyorsan kiderül, ha valamit nem jól definiáltunk.
a. Számlaszám
Példányokról készülő statisztikát lehet a számlaszám (csoportos leltárkönyv) szerint is bontani. Ennek főleg állomány statisztika készítésénél van értelme, ez lesz a gyarapodási lista.
b. Állományonként
Ezt a bontást használhatjuk pl. állomány statisztika összesítő nyomtatásakor. Ez a bontás így definiálva nem csak példányokra jó, hanem kölcsönzésekre is. Utóbbi esetben a kölcsönzött dokumentum állományát adja meg. Nem kell tehát külön bontást csinálni, ami a példányok állományát adja, és egy másikat, ami a kölcsönzött példányok állományát adja.
c. Olvasói kategóriánként
Ezt a bontást használhatjuk szinte mindig, ha olvasók kategóriája szerint szeretnénk a statisztika sorok bontását. Ily módon definiálva nem csak olvasók, hanem kölcsönzések (kölcsönző olvasó), és tartozások (tartozó olvasó) kategóriáját is meg tudja adni. Ez azért jó, mert elég egy bontást definiálnunk, és azt többféle statisztikához is fel lehet használni.
A rendszergazda feladata, hogy jogokat definiáljon, és ezeket a dolgozókhoz rendelje. A jogok is rekordokban vannak tárolva, a többi rekordhoz hasonlóan lehet őket létrehozni és módosítani.
A jogok segítségével oldható meg az is, hogy ugyanazt a rekordot különböző dolgozók (olvasók) más-más ablakokkal tudják megnézni.
A jogokat egyelőre két szinten tudjuk használni. Azokat a jogokat, amiket minden dolgozóra (vagy olvasóra) ki akarunk terjeszteni, a Rendszer adatai közé kell felvenni (Default dolgozói jogok, Default olvasói jogok). Azokat a jogokat pedig, amiket csak egy-egy dolgozónak akarunk adni, annak a dolgozónak a jogai közé kell beraknunk (dolgozó módosítása). Terveink között szerepel, hogy csoportokhoz is lehessen jogokat rendelni.
A rendszergazdának nem kell jogokat adni, neki úgyis mindig mindenhez joga van. Az Adatfájl modulok-at pedig nem érdemes változtatnia, mert más modulokban esetleg nem tud bármit elvégezni.
Minden adatfájlra megadható, hogy milyen modullal (ablakkal) lehet ebbe az adatfájlba tartozó rekordokat:
Az adatfájlokat egyelőre még a sorszámukkal kell megadni (lásd: DBSTRUCT program). Későbbi fejlesztés lesz, amikor majd a nevüket is meg lehet adni.Egyelőre csak az InfoKer által készített modulok közül lehet választani. Aki más adatlapot szeretne egyes adatfájlokhoz használni, az InfoKer-től rendelheti meg. Későbbi terveink között szerepel egy olyan program, amivel az adatlapok szabadon definiálhatók.
Ha a négy modul közül csak egyet akarunk megváltoztatni, akkor a többi háromba írjuk be a 'default' értéket.
1. példa:
Jog megadásával megváltoztathatjuk az alapértelmezett megnézési formátumot. Egy keresés végén a találatokat megnézés módban ablakosan nézve alapértelmezetten az ablak űrlapos formáját látjuk. A változtatás az űrlapos formát változtathatja meg, pl. dokumentumok esetében cédula formává.
Jogok adásával az alapértelmezettől többféle cél érdekében eltérhetünk, pl:
A megnézési formátum megváltoztatásához a dolgozó űrlapjának két mezőjét kell módosítani:
Minden adatfájlra megadható, hogy mihez van joga a felhasználónak. A következő lehetőségek vannak (természetesen több is választható egyszerre):
Az adatfájlokat egyelőre még a sorszámukkal kell megadni (lásd: DBSTRUCT program). Későbbi fejlesztés lesz, amikor majd a nevüket is meg lehet adni.Az ÖSSZES adatfájl használatára vonatkozó megengedő illetve tiltó jogot adhat meg az alábbi módokon:
Ha sorszámnak -1 értéket ír be, akkor a bejelölt jogok az összes adatfájlra érvényessé válnak, a jelöletlenek a máshol beállított vagy alapértelmezés szerinti érvényességgel változatlanok maradnak.
Ha sorszámnak -2 értéket ad, akkor a jelöletlen jogok az összes adatfájlra törlődnek, a bejelöltek a máshol beállított vagy alapértelmezés szerinti érvényességgel változatlanok maradnak.
2. példa:
Ha egy dolgozónak meg akarjuk tiltani, hogy bármit is töröljön vagy módosítson, akkor egy jog definiálásánál a következőket állítsuk be: Adatfájl sorszáma legyen -2, és csak a Megnézhet, Nyomtathat, Bevihet mezőket jelöljük be.
A következő (ún. rendszer) jogok közül is megadható egyszerre több is:
A nyomtatási jog megadásakor a következő lehetőségek közül kell azokat bejelölni, amikhez a felhasználónak majd joga lesz. Ha egyet sem jelölünk be, akkor sehova sem nyomtathat.
!!! Ez a projekció megadási lehetőség meg fog szűnni! Helyette a
!!! keresőkérdés használható, amit sokkal egyszerűbb megadni.
!!! Használata megegyezik a régi projekcióval
!!! Lásd: <kerkerd.txt>
A projekció egy olyan (több lépésből álló) művelet, ami egy találati halmazból egy másik találati halmazt képez. Egyes rekordokra adott a "Keresés" és a "Részletezés" lehetősége. Vagyis meg tudjuk keresni mondjuk egy adott szerző könyveit, és a konkrét könyv esetében meg tudjuk nézni szerzőit. A projekció arra való, hogy egy halmaz elemeire is meg tudjuk tenni ugyanezt. Azaz: a halmazba gyűjtött szerzők könyveit kereshessük, vagy a halmazba lekeresett könyvek szerzőit gyűjtsük össze. A projekció definiálásánál szabályokat kell megadnunk. Ezek mondják meg, hogy milyen rekordok esetében milyen módon tudunk tovább menni az eredmény rekordok felé. Kétféle szabályt tudunk megadni:
A programhoz adott példa adatbázisban néhány projekciót is definiáltunk, hogy egyszerűen ki lehessen őket próbálni.
Példák
1. Könyvek összes szerzője
Neve: Könyvek összes szerzője
Projekció adatai:
Rekordtípus: 53 (DOKUMENTUM)
Mező sorsz.: 70 (SZERZO)
eredmény Rekordtípus-ok:63 (ALKOTO) es 57 (TESTULET)
2. Szerzők összes könyve
Neve: Szerzők összes könyve
Projekció adatai:
Rekordtípus: 63 (ALKOTO)
Indexfájl: 74 (SZERZOJE)
Rekordtípus: 57 (TESTULET)
Indexfájl: 74 (SZERZOJE)
eredmény Rekordtípus-ok:53 (DOKUMENTUM)
Hamarosan
A TextLib egy háromszintű help (segítség, súgó) rendszert tartalmaz. Kérhet segítséget arra vonatkozóan, hogy mire való az az ablak, ami éppen a képernyőn van (Aktuális ablak mire való), megtudhatja, hogy mit tehet a billentyűzettel és az egérrel abban a mezőben, amiben éppen van (Program használata), valamint azt is megkérdezheti, hogy mi a kitöltési utasítása az éppen aktuális mezőnek (Adatbázis szerkezet). Ez a háromféle help különböző billentyűkkel, vagy egy menüből választással érhető el.
| Billentyű | mire jó |
|---|---|
| F1 | Aktuális ablak mire való |
| SHIFT/F1 | Adatbázis szerkezet |
| SHIFT/F2 | Program használata |
| F2 | Help menü |
| egér középső gomb | Help menü |
A TextLib adatmezőibe előre írt névelők a rendezés szelektivitását rontják, illetve szavas indexelésnél a gyakori előfordulás miatt az információtartalmuk csekély. Ezért az alábbi listában szereplő névelők a sorba rendezendő karaktersorozatokból kimarad(hat)nak.
A névelők:
Az indexelésből kimaradó szavak listája
A TextLib adatmezőibe írt egyes szavak a rendezés szelektivitását rontják, illetve szavas indexelésnél a gyakori előfordulás miatt az információtartalmuk csekély. Ezért az alábbi listában szereplő szavak, az úgynevezett stopword-ök a sorba rendezendő karaktersorozatokból kimarad(hat)nak.
A stopword-ök: